Livrable WP1 - L1 : Segmentation phonétique
Contexte et objectifs
Description du corpus
CLeLfPC - Corpus de Lecture en LfPC, contient des enregistrements audio/vidéo de lecture à voix haute en codant en Langue française Parlée Complétée. Le corpus a été enregistré en août 2021 à l'occasion du stage organisé par l'ALPC (https://alpc.asso.fr).
Une série de 10 thèmes de lecture avait été établie, elle peut être consultée à cette adresse : https://sppas.org/LFPC/.
Chacun des 10 thèmes est constitué de 4 sessions distinctes :
- enregistrement audio/vidéo de 32 syllabes "CV" isolées (1 seule clé produite pour chaque syllabe),
- enregistrement audio/vidéo de 32 mots ou expressions,
- enregistrement audio/vidéo de phrases isolées,
- enregistrement audio/vidéo d'un texte.
Le corpus est constitué des enregistrements de 25 thèmes par 23 participants.
Objectif
Le corpus doit être enrichi d'annotations pour pouvoir être exploité dans le cadre de ce projet. En premier lieu, il est nécessaire de connaître quels sont les phonèmes qui ont été prononcés, et à quel moment ils l'ont été.
Dix thèmes ont été annotés automatiquement et corrigés manuellement au niveau phonétique.
En savoir plus...
- Publication de référence : Brigitte Bigi, Maryvonne Zimmermann, Carine André (2022). CLeLfPC: a Large Open Multi-Speaker Corpus of French Cued Speech. In Proceedings of The 13th Language Resources and Evaluation Conference, pp. 987-994, Marseille, France.
- Fiche technique du corpus
- Accès aux données
Enregistrements annotés
Ci-dessous, se trouve la liste des enregistrements pour lesquels nous disposons de la segmentation phonétique, et leur description :
- 01_CH_dd640f : Thème 1, femme, droitière, codage main droite, codeuse professionnelle
- 02_VT_dd640f : Thème 2, femme, droitière, codage main droite, codeuse professionnelle
- 03_AM_dd630f : Thème 3, femme, droitière, codage main droite, codeuse professionnelle
- 04_RJ_gg330m : Thème 4, homme, gaucher, codage main gauche
- 05_ML_gg540f : Thème 5, femme, gauchère, codage main gauche
- 06_FL_dd620f : Thème 6, femme, droitière, codage main droite, codeuse professionnelle
- 07_LW_dd641f : Thème 7, femme, droitière, codage main droite, avec surdité
- 08_HH_gd440f : Thème 8, femme, droitière, codage main gauche
- 09_LM_gd640f : Thème 9, femme, droitière, codage main gauche, codeuse professionnelle
- 10_ED_dd320f : Thème 10, femme, droitière, codage main droite
Les fichiers (audios, vidéos, annotations) sont déposés sous les termes de la licence publique CC-By-NC-4.0. Ils peuvent être téléchargés à partir de la version 6 du dépôt https://www.ortolang.fr par tout membre d'un Etablissement Supérieur de la Recherche. Pour toute autre demande, envoyer un e-mail à brigitte.bigi[.at.]cnrs.fr.
Description des étapes réalisées pour obtenir les annotations
Recherche des unités inter-pausales
Les unités inter-pausales (IPUs) sont des portions audibles de fichier audio, séparés par des segments inaudibles (silences). La durée minimale des segments inaudibles a été fixée à 200ms. Ces unités sont déterminées automatiquement par le logiciel SPPAS, avec l'annotation "Search for IPUs".
Une fois obtenue, cette annotation doit être corrigée, afin de :
- [requis] vérifier les frontières de début et fin des portions audibles,
- [optionnel] supprimer les portions audibles qui ne présentent aucun intérêt (bruit, erreur de détection, etc).
Transcription orthographique
La transcription orthographique a été réalisée manuellement, après écoute des IPUs, dans le logiciel Praat. Cette transcription doit respecter une convention, qui est décrite en suivant ce lien. Le principe de cette convention repose sur l'idée que chaque "son" qui est présent dans l'enregistrement doit être transcrit. Par exemple, les rires, les hésitations ou les répétitions doivent être mentionnés.
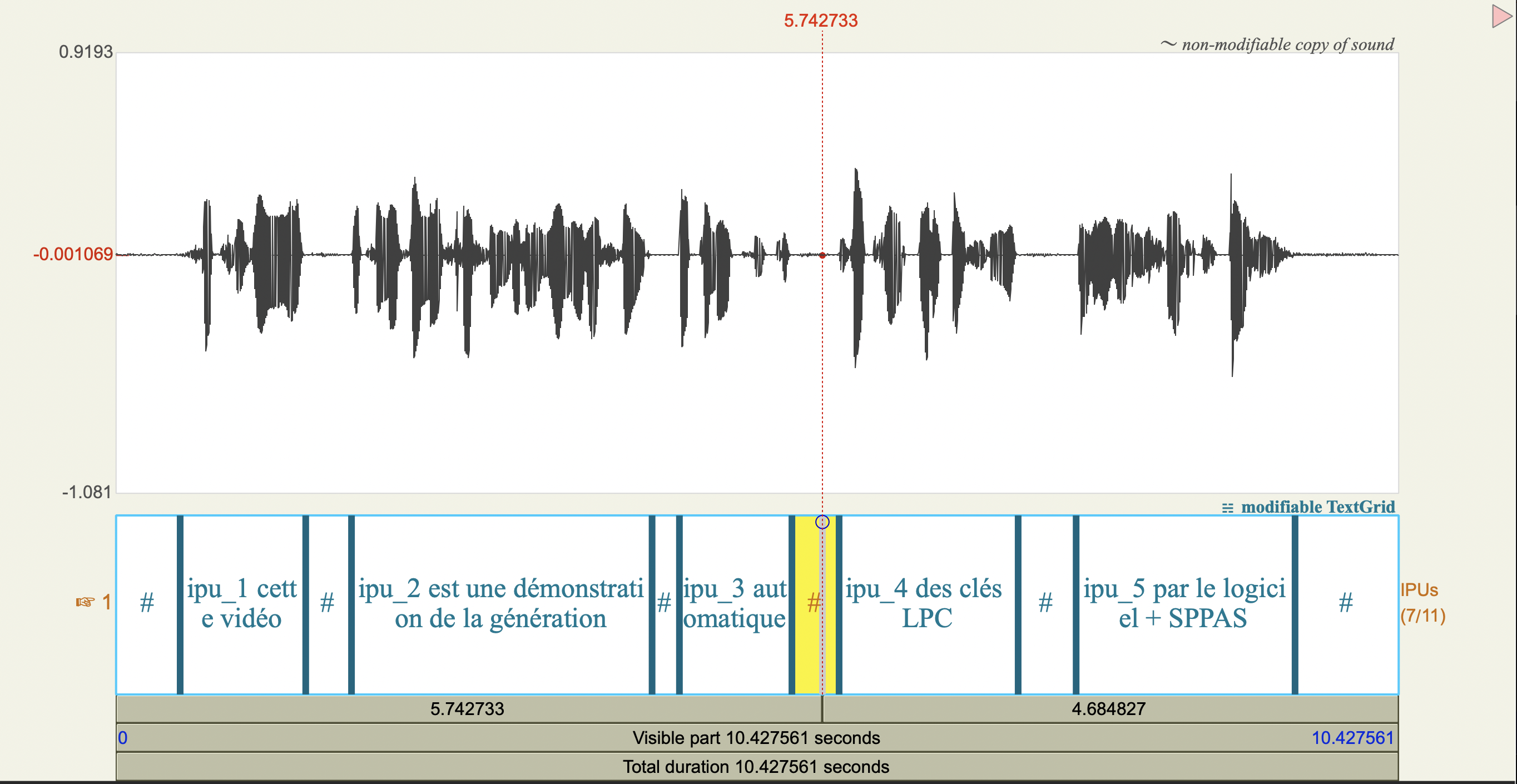
Transcription phonétique
La transcription phonétique est obtenue avec SPPAS en effectuant deux annotations automatiques : "Text normalization" et "Phonetization". La première supprime la ponctuation, transforme les chiffres dans leur version écrite (par exemple "2" devient "deux"), et segmente en mots. La seconde annotation transforme le texte normalisé en séquences de phonèmes. Lorsqu'un mot se prononce de différentes façons, toutes ses variantes sont conservées.
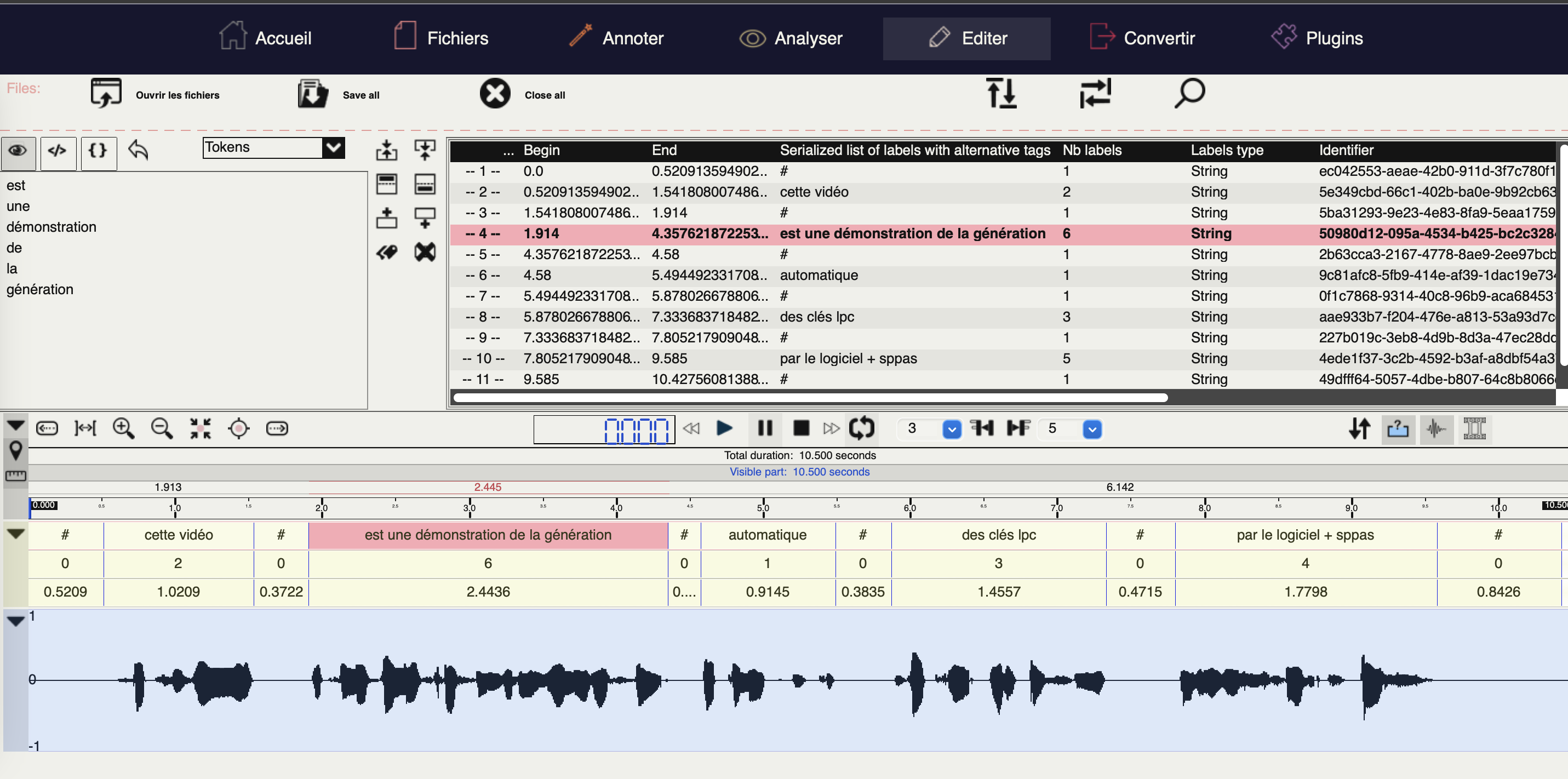
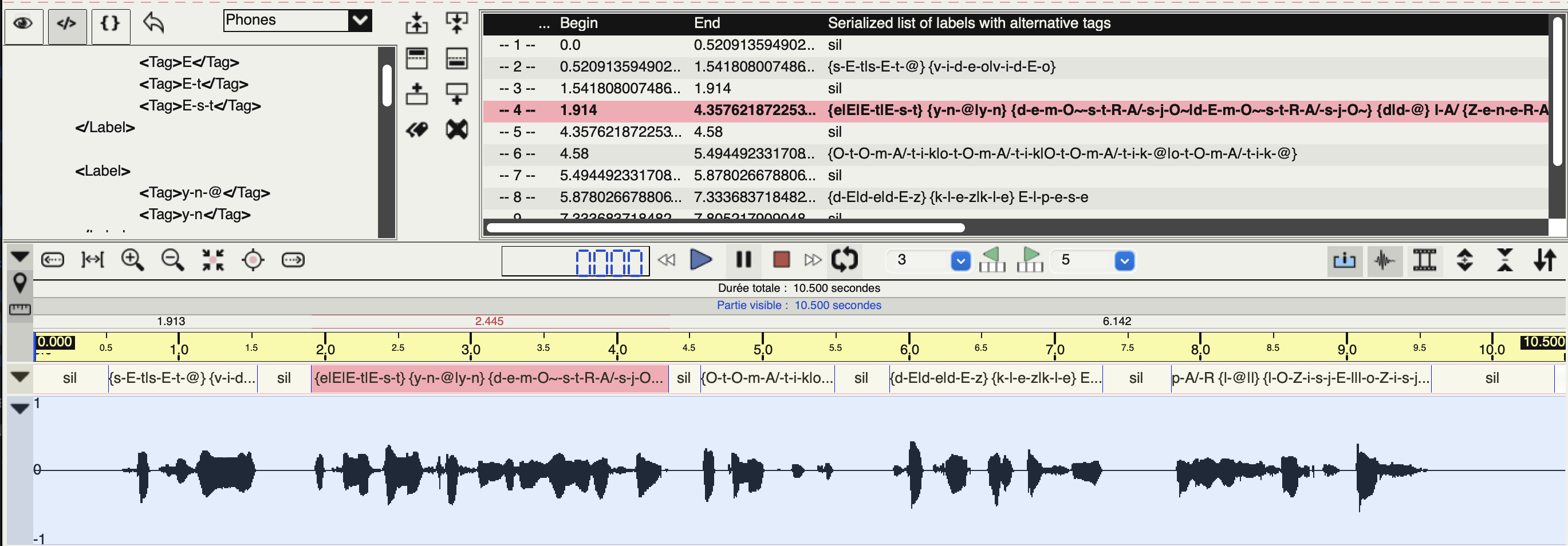
Afin d'obtenir une annotation de qualité, nous avons corrigé manuellement le résultat de la phonétisation, en sélectionnant la prononciation appropriée de chaque mot, dans l'éditeur de SPPAS.
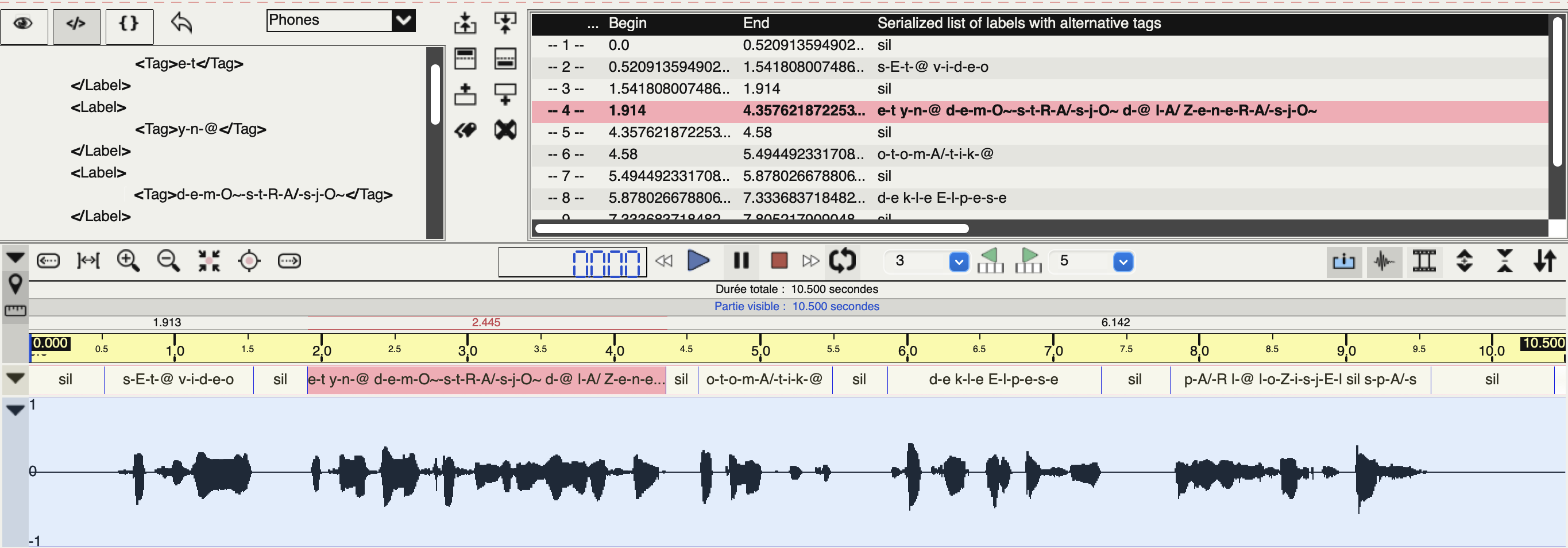
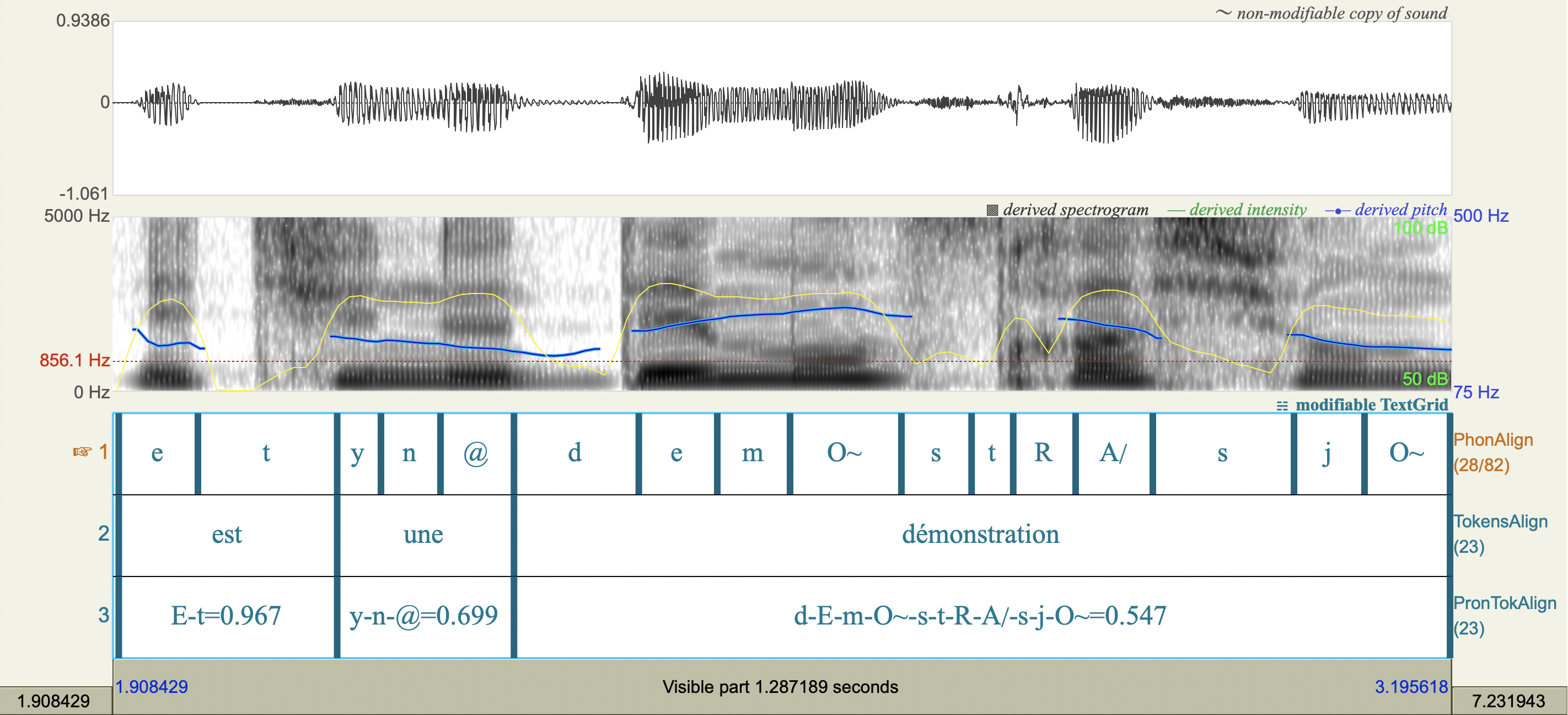
Alignement temporel des phonèmes
Dans un premier temps, cette annotation est effectuée automatiquement avec SPPAS ; elle permet d'obtenir l'alignement temporel entre les phonèmes et l'enregistrement audio. Dans un second temps, cet alignement est corrigé manuellement avec le logiciel Praat.
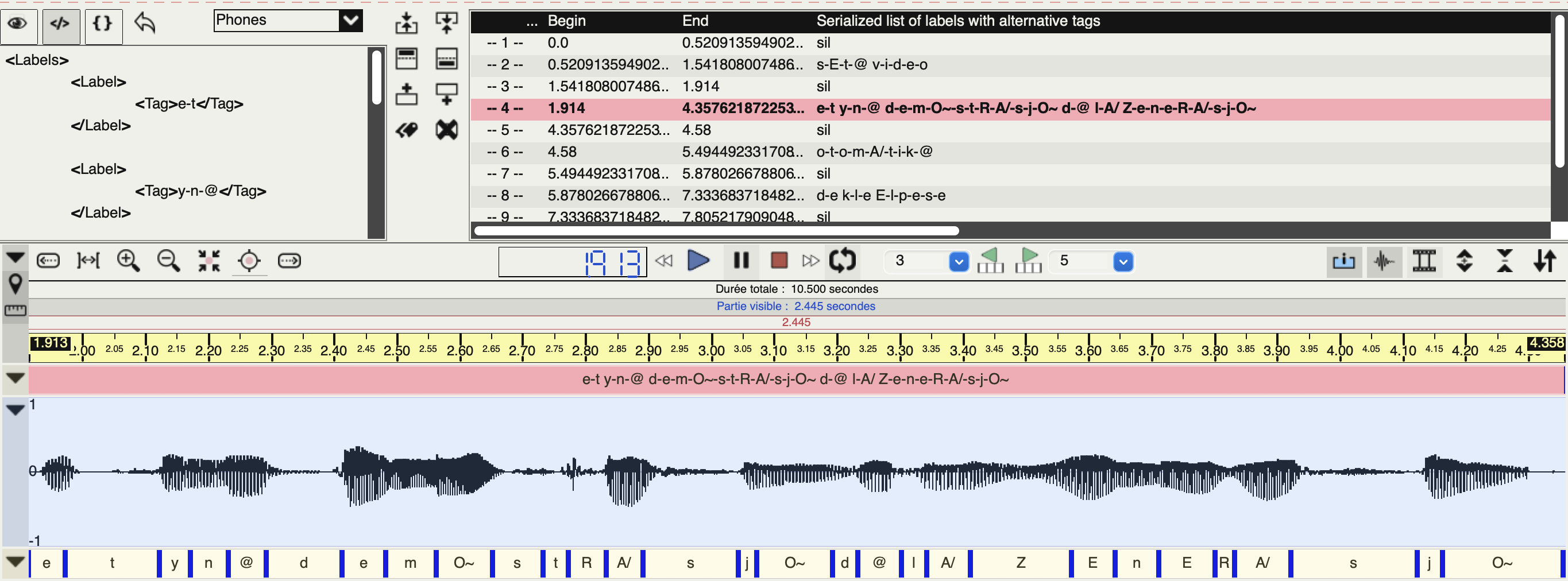
A l'issue de ce processus, nous obtenons un alignement temporel des phonèmes.
Contributeurs
Annotation manuelle du corpus : Léa Delaporte (août 2023)
Annotation automatique du corpus, gestion des données : Brigitte Bigi (2023)
À propos
- Rédaction du document : Brigitte Bigi
- Licence du document : GNU documentation libre - FDL 1.3
- Copyright 2023 Brigitte Bigi, CNRS, Laboratoire Parole et Langage, France
- URL du document : https://auto-cuedspeech.org/wp1l1.html
- Dernière mise à jour : septembre 2023