Recherche
Cette page présente les travaux scientifiques associés aux technologies de codage en LfPC décrites sur ce site. L'objectif est de développer, évaluer et diffuser des méthodes et des outils permettant de représenter le codage de façon fiable, et de produire des supports utiles aux personnes sourdes, aux familles et aux professionnels.
Le reste de la page s'adresse surtout à un public scientifique, et aux plus curieux.
Les travaux portent sur la génération automatique du codage LfPC, sur sa représentation visuelle, et sur la création de ressources, avec une attention particulière à l'évaluation, à la reproductibilité et au partage.
Table des matières :
Objectifs et approche méthodologique
À partir d'un fichier audio-vidéo et de sa transcription orthographique, nous cherchons à décrire au mieux le fonctionnement du codage par des codeurs afin de créer un système qui prédit le codage Cued Speech/LfPC à effectuer. Le système a pour but d'ajouter automatiquement ce codage de la main à une vidéo pré-enregistrée. Pour chacune des questions abordées, nous nous appuyons dans un premier temps sur l'expertise en codage des membres experts du projet, afin de définir les paramètres du système et son fonctionnement. En parallèle, des vidéos de codeurs humains sont annotées et permettent d'en étudier son fonctionnement et d'en déduire des modèles. La réponse scientifique privilégiée lors de la conception placera les compétences et les connaissances des experts au cœur du système, en minimisant ainsi la quantité de données à observer pour apprendre un modèle/une représentation.
Nous avons l'objectif de modéliser la réalité du codage « Cued Speech » afin de capturer la variabilité des données et permettre l'apprentissage automatique à partir d'échantillons de la langue. Il s'agira de proposer des stratégies et des outils d'annotations (semi-)automatiques pour générer le codage et le représenter sur des supports audio-visuels.
Malgré les nombreux travaux démontrant ses avantages, il n’existe que peu de ressources en LfPC. Aussi, ce projet vise à développer des ressources pour l’apprentissage et la pratique de la LfPC. Les supports textuels de la ressource seront issus du projet ANR ALECTOR, ce sont des textes simplifiés pour faciliter la lecture (Gala et al. 2020). L’idée est ici d'enregistrer le corpus ALECTOR et de le coder automatiquement en LfPC afin de fournir des supports de lecture et d’entraînement pour les enfants sourds et malentendants, et de rendre les vidéos accessibles via une plateforme web. Notre objectif est également de proposer des exercices d’entraînement et des extraits de phrases courtes, dans le but de permettre une pratique ciblée de certaines clés. Pour construire ces supports, nous proposerons une progression de difficulté fondée sur la littérature relative à l’apprentissage de la lecture (par ex. Dehaene, 2011 ; Colé & Sprenger Charolles, 2023).
Logiciels créés
Auto-CS
Auto-CS est un système logiciel intégré au logiciel SPPAS (via un mécanisme de spin-off) permettant la génération automatique du code en Langue française Parlée Complétée. Il repose sur une architecture modulaire structurée en quatre traitements successifs — détermination des clés (what), synchronisation temporelle des transitions de main (when), calcul spatial des positions et trajectoires à partir de repères faciaux (where), et rendu visuel vidéo (how) — formalisant un processus complet d’annotation et de visualisation automatique.
Auto-CS consiste en un système complet et opérationnel de génération automatique de Langue française Parlée Complétée à partir d’une vidéo, de son signal audio et d’une transcription. Il formalise l’ensemble du processus de codage en quatre modules interdépendants : détermination des clés à partir des phonèmes par automate déterministe, modélisation temporelle des transitions manuelles (plusieurs modèles paramétrés), calcul spatial des positions et trajectoires à partir des 68 repères faciaux, puis rendu graphique configurable d’une main virtuelle synchronisée.
Le système intègre des modèles linguistiques explicites, des règles temporelles proportionnelles fondées sur les bornes acoustiques, des formules géométriques reproductibles pour le positionnement, et un moteur de rendu évalué expérimentalement auprès d’utilisateurs sourds (80,7 % de décodage contre 92,3 % pour un codage expert). L’ensemble est implémenté en Python, diffusé sous licence AGPL et constitue le premier cadre ouvert, reproductible et scientifiquement validé pour la génération automatique de LfPC en vidéo.
Ce programme innovant couvre également la génération de code à partir d’un texte seul, sans signal audio ni vidéo. Dans ce cas, la chaîne de traitement s’appuie sur la normalisation, la phonétisation, puis la conversion phonèmes→clés via l’automate déterministe du module “what”, indépendamment des modules temporels et spatiaux. Cette modalité « texte → code » d’Auto-CS est mise en œuvre via une application "TextCueS", outil dédié à la génération et à la pratique du codage à partir d’un texte seul, en rendant le processus explicite et contrôlable. L’utilisateur suit un parcours guidé en trois étapes (Texte → Sons → Code).
Cette seconde modalité étend Auto-CS au-delà du pipeline « vidéo+audio+transcription → vidéo codée » dans SPPAS. Elle offre une génération à partir de texte via une interface graphique (dans SPPAS et en ligne sur le site web du projet). Elle est conçue pour plusieurs langues dès lors que des règles de codage existent (actuellement français et anglais américain).
Le dépôt d'invention pour la version 2.0 est en phase de pré-étude auprès de la SATT Sud-Est.
SPPAS + Auto-CS
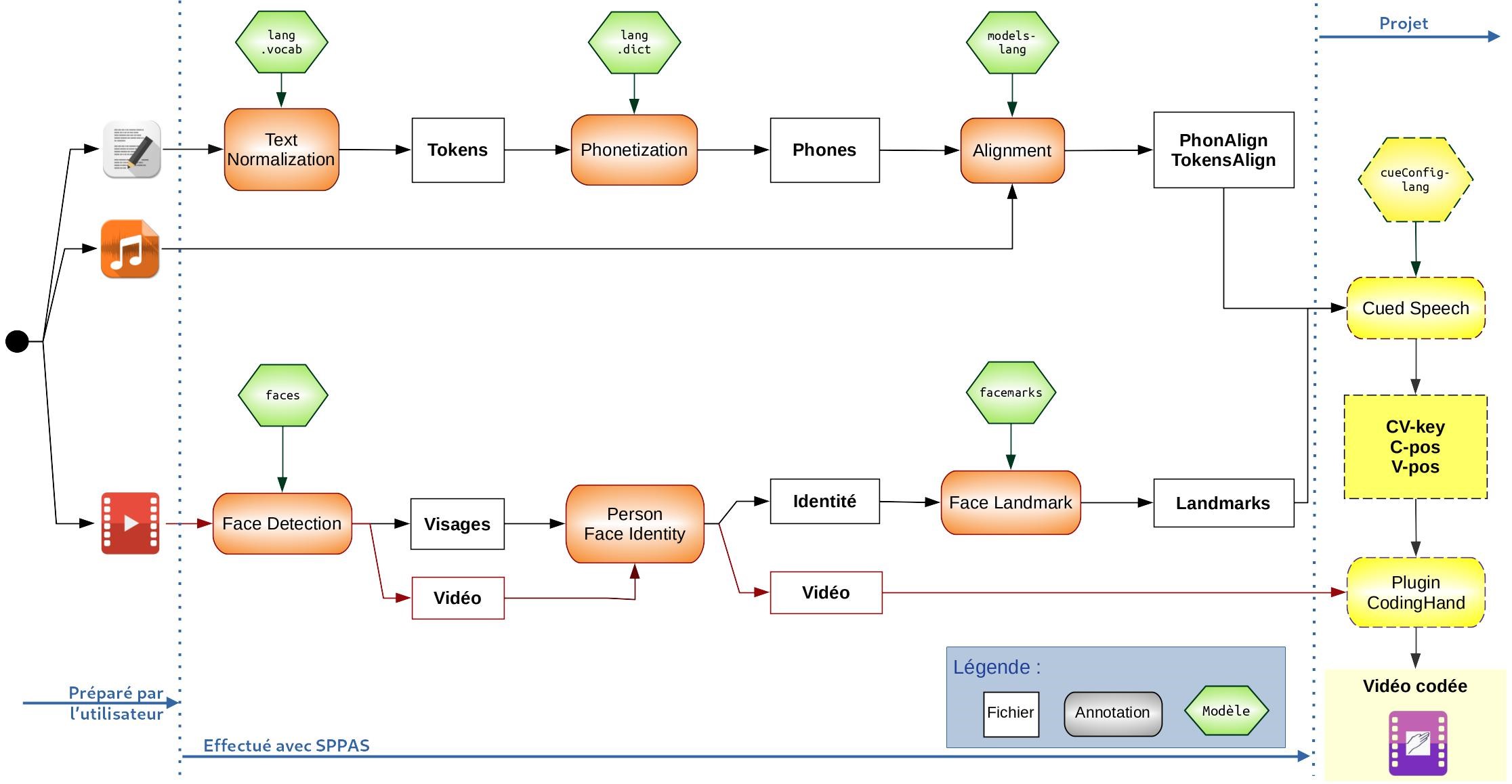
Le schéma ci-après montre les étapes requises de SPPAS dans le cadre de ce projet, avec le module et le spin-off que nous avons ajouté (en jaune pointillé). Il faut noter ici que, bien qu'elles soient nombreuses, chacune de ces étapes n'est réalisée qu'en « un clic » dans l'interface graphique. En utilisation automatique, toutes les annotations sont sélectionnées, puis le processus est lancé en une seule fois. En utilisation semi-automatique, chaque fichier intermédiaire peut être manuellement vérifié et corrigé avant de lancer l'annotation suivante. Un exemple d'utilisation partielle de ce processus est déroulé ici :
Suivi des versions :
- 4.10 (avril 2023) : Pour la langue française uniquement, SPPAS peut produire la suite de clés à coder à partir d'une transcription orthographique, accompagnée ou non d'un fichier audio. Système à base de règles définies par des experts du codage (WP2-L1).
- 4.11 (juin 2023) : La preuve de concept a été re-programmée et donc débuggée. Elle fonctionne avec n'importe quelle vidéo, et pas uniquement la démo. L'angle du bras est différent selon la clé.
- 4.12 (août 2023) : SPPAS permet de corriger manuellement les annotations, y compris les annotations vidéo.
- 4.13 (oct. 2023) : la main codeuse peut être intégrée à la vidéo avec différentes options d'affichage, via une interface graphique (minimale) spécifique. Fonctionne pour la démo uniquement, et en mode de debug seulement. C'est un prototype de la future interface.
- 4.17 (jan. 2024) : SPPAS peut produire les clés avec différentes règles de synchronisation audio-main, avec l'introduction d'un modèle à base de règles définies par des experts du codage (WP3-L1).
- 4.22 (juil. 2024). Livrable "Système version 1" : trois modèles différents de l'angle de l'avant-bras ont été introduits pour afficher la main sur la vidéo ; deux modèles différents permettent d'estimer la position des voyelles par rapport au visage ; six séries de photos de mains sont proposées ainsi que deux séries de mains dessinées ; des filtres peuvent être appliqués à la main dessinée pour ajouter des informations.
- 4.25 (31 mars 2025). Livrable "Système version 2" : un nouveau modèle pour l'angle de l'avant-bras a été introduit pour afficher la main sur la vidéo ainsi que de nouveaux modèles permettent d'estimer la position des voyelles par rapport au visage ; les modèles utilisés par défaut ont été changés et de nouvelles options de génération sont mises à disposition.
- 4.26 (26 juin 2025). SPPAS peut produire la suite de clés à coder à partir d'une transcription orthographique, accompagnée ou non d'un fichier audio pour l'anglais américain. Système à base de règles définies par des experts du codage (WP2-L2). Le codage automatique n'est plus intégré à SPPAS : il a migré dans le "spin-off" "Auto-CS".
- 4.31 (18 février 2026) et "Auto-CS" version 2.0. Révision des règles pour l'anglais américain. Dans TextCueS, le résultat du codage d'une chaîne textuelle n'est plus une suite continue de clés : cette séquence de clés est segmentée en mots.

Ressources créées
Capsules avec vidéos codées automatiquement
Les enregistrements relatifs à la création des capsules ont été réalisés en avril 2024. La synchronisation audio/vidéo, la transcription orthographique (manuelle), les annotations phonétiques (automatiques) et vidéos (automatiques) ont été réalisées en août 2024. Une première version des vidéos codées a été produite en septembre 2024. Elles sont en cours d'analyse.
Publications et communications scientifiques
Publications
Brigitte Bigi (2023). An analysis of produced versus predicted French Cued Speech keys. In 10th Language & Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics, ISBN: 978-83-232-4176-8, pp. 24-28, Poznań, Poland.
Cued Speech is a communication system developed for deaf people to complement speechreading at the phonetic level with hands. This visual communication mode uses handshapes in different placements near the face in combination with the mouth movements of speech to make the phonemes of spoken language look different from each other. This paper presents an analysis on produced cues in 5 topics of CLeLfPC, a large corpus of read speech in French with Cued Speech. A phonemes-to-cues automatic system is proposed in order to predict the cue to be produced while speaking. This system is part of SPPAS-the automatic annotation an analysis of speech, an open-source software tool. The predicted keys of the automatic system are compared to the produced keys of cuers. The number of inserted, deleted and substituted keys are analyzed. We observed that most of the differences between predicted and produced keys comes from 3 common position's substitutions by some of the cuers.
Núria Gala, Brigitte Bigi, Marie Bauer (2024). Automatically Estimating Textual and Phonemic Complexity for Cued Speech: How to See the Sounds from French Texts In The 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation (LREC-COLING), pp. 1817-1824, Turin, Italie.
In this position paper we present a methodology to automatically annotate French text for Cued Speech (CS), a communication system developed for people with hearing loss to complement speech reading at the phonetic level. This visual communication mode uses handshapes in different placements near the face in combination with the mouth movements (called ‘cues’ or ‘keys’) to make the phonemes of spoken language look different from each other. CS is used to acquire skills in lip-reading, in oral communication and for reading. Despite many studies demonstrating its benefits, there are few resources available for learning and practicing it, especially in French. We thus propose a methodology to phonemize written corpora so that each word is aligned with the corresponding CS key(s). This methodology is proposed as part of a wider project aimed at creating an augmented reality system displaying a virtual coding hand where the user will be able to choose a text upon its complexity for cueing.
Brigitte Bigi, Núria Gala (2024). Preuve de concept d'un système de génération automatique en Langue française Parlée Complétée In 35ème Journées d’Études sur la Parole (JEP). Toulouse, France.
La Langue française Parlée Complétée (LfPC) est un système de communication développé pour les personnes sourdes afin de compléter la lecture labiale avec une main, au niveau phonétique. Il est utilisé par les enfants pour acquérir des compétences en lecture, en lecture labiale et en communication orale. L’objectif principal est de permettre aux enfants sourds de devenir des lecteurs et des locuteurs compétents en langue française. Nous proposons une preuve de concept (PoC) d’un système de réalité augmentée qui place automatiquement la représentation d’une main codeuse sur la vidéo pré-enregistrée d’un locuteur. Le PoC prédit la forme et la position de la main, le moment durant lequel elle doit être affichée, et ses coordonnées relativement au visage dans la vidéo. Des photos de mains sont ensuite juxtaposées à la vidéo. Des vidéos annotées automatiquement par le PoC ont été montrées à des personnes sourdes qui l’ont accueilli et évalué favorablement.
Mélanie Lancien, Brigitte Bigi (2025). French Cued Speech rhythm: first findings on the relationship between hand position and segments' duration. In 11th Language & Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics, ISBN: --, pp. --, Poznań, Poland.
Cued Speech (CS) is a visual system that clarifies spoken language by combining lipreading with hand gestures encoding phonological segments. Each CS key, roughly corresponding to a CV syllable, combines a hand shape (consonant) and a spatial position on the face (vowel); these associations are universal across languages. In French CS, 21 consonants use eight hand shapes and 14 vowels use five positions. Despite its potential, CS remains understudied by linguists, leaving questions about its use, its structure, and the speech-gesture synchronization. This paper begin to explore these relationships by focusing on CS rhythm, primarily through the study of spoken vowels and syllables durations and their link to the hand's target position on the face, hand's shape, type of syllable, and type of reading activity. The experiment uses annotated video data from the CLeLfPC corpus, comprising over 3,700 keys produced by five experienced users. A statistical analysis via generalized mixed-effects models revealed that Hand Target Position significantly affected vowel and syllable duration (p < 0.005, R2 = 9% and 6%). These findings contribute to a better understanding of the spatiotemporal organization of LfPC and may inform future models of gesture planning and cue synthesis.
Brigitte Bigi (2025). Spatial Analysis of Hand Positions in French Cued Speech (LfPC). In 16th International Conference on Linguistic Research and Application, Paris, France.
Speech production relies on both acoustic and visual cues. While lip movements convey valuable information, many phonemes remain visually ambiguous. Cued Speech is a visual coding system that complements lipreading by combining mouth shapes with hand cues — specific handshapes and positions around the face — that encode consonants and vowels. It provides full visual access to spoken language and supports phonological awareness, literacy development, and oral language acquisition in deaf or hard-of-hearing individuals. This study investigates the spatial distribution of vowel-related hand positions in French Cued Speech (LfPC), which uses eight handshapes for consonants and five distinct positions for vowels.
Brigitte Bigi (2025). Bridging the Gap: Design and Evaluation of an Automated System for French Cued Speech. In Proceedings of the 8th International Conference on Natural Language and Speech Processing (ICNLSP-2025), pp. 8-18, Odense, Denmark.
Access to spoken language remains a challenge for deaf and hard-of-hearing individuals due to the limitations of lipreading. Cued Speech (CS) addresses this by combining lip movements with hand cues-specific shapes and placements near the face-making each syllable visually distinct. This system complements cochlear implants and supports oral language, phonological awareness, and literacy. This paper introduces the first open-source system for automatically generating CS in video format. It takes as input a video recording, the corresponding audio signal, and an orthographic transcript. These elements are processed through a modular pipeline, which includes phonetic mapping, temporal alignment, spatial placement, and real-time rendering of a virtual coding hand. The system is multilingual by design, with current resources focused on French. An evaluation under varied conditions showed decoding rates up to 92% for manually coded stimuli, and averages exceeding 80% for automatically generated ones. Visual clarity of hand shapes proved more critical than timing or angle. Stylized designs and frontal views enhanced decoding performance, while attempts at naturalistic rendering or visual effects often degraded it. These findings indicate that visual abstraction improves readability. This work provides a reproducible and scientifically grounded framework for visual phonetic encoding, and delivers a practical tool for education, accessibility, and research.
Conférences invitées
Núria Gala, Brigitte Bigi (2023). Création de ressources en langue française parlée complétée pour faciliter l'accès à la langue orale via l'écrit Journée scientifique de l'Institut des Sciences et Techniques de la Réadaptation, Institut des Sciences & Techniques de la Réadaptation, 3 juin 2023, Lyon, France.
La Langue française Parlée Complétée (LfPC ou Cued Speech) est un codage des sons via des informations visuelles : chaque son est représenté avec une forme de main pour une consonne et une position autour du visage pour une voyelle. La LfPC est utilisée par le public sourd et malentendant pour acquérir de bonnes compétences en lecture, en lecture labiale et en expression orale. Il permet notamment aux enfants sourds ou malentendants de devenir des bons lecteurs, compétence indispensable pour tous les apprentissages. Malgré les nombreux travaux démontrant ses avantages, il n’existe que peu de ressources en LfPC. Aussi, ce projet vise à développer des ressources pour l’apprentissage et la pratique de la LfPC. Nous nous proposons de développer un système de réalité augmentée qui place automatiquement la représentation d’une main codeuse sur une vidéo d’un locuteur pré-enregistré. Un logiciel de codage automatique LfPC et des bibliothèques de vidéos codées à but pédagogique seront ainsi produits en respectant tous les critères de l’Open Science. Le système de codage sera développé sur la base d’observations d’un corpus de 4 heures d’enregistrement audio/vidéo (Bigi et al., 2022). Les supports textuels de la ressource seront issus du projet ANR ALECTOR, ce sont des textes simplifiés pour faciliter la lecture (Gala et al. 2020).
Séminaires

Voir les sons avec du "Cued Speech" automatisé : Clés produites versus clés prédites
Réunion équipe VESPA - Variation Et Singularité dans la PArole, Laboratoire Parole et Langage, 3 juin 2023, Aix-en-Provence, France.
Voir les sons avec du "Cued Speech" automatisé : la réalité augmentée au service des personnes sourdes
Journée annuelle scientifique du Laboratoire Parole et Langage, 23 juin 2023, Aix-en-Provence, France.
Un outil de réalité augmentée pour coder automatiquement les sons du français
1er Afterwork de la Cognition, organisé par le LPL en partenariat avec l'Institut Carnot Cognition, autour du thème "Langage et apprentissage", 6 juin 2024, Aix-en-Provence, France.
SPPAS : coder automatiquement les sons en LfPC
Journée annuelle scientifique du Laboratoire Parole et Langage, 1-2 juillet 2025, Aix-en-Provence, France.

14 mars 2025, Nancy, France.

7 juillet 2025, Superbagnères, France.
Livrables
Collecte et annotation de corpus codés
Segmentation phonétique de CLeLfPC
Cette annotation permet d'indiquer quel phonème a été prononcé, et à quel moment. Elle concerne 10 locuteurs du corpus CLeLfPC, version 6, déposée sous licence CC-By-NC-4.0 sur https://www.ortolang.fr.
Annotation en clés de CLeLfPC
Cette annotation permet d'indiquer quelles clés ont été réalisées durant la lecture. Elle concerne 10 locuteurs du corpus CLeLfPC, version 8, déposée sous licence CC-By-NC-4.0 sur https://www.ortolang.fr.
Transitions des clés de CLeLfPC
Cette annotation permet d'indiquer à quels moments ont lieu les transitions des positons et des configurations de la main durant la lecture. Elle concerne 5 locuteurs du corpus CLeLfPC, version 10, déposée sous licence CC-By-NC-4.0 sur https://www.ortolang.fr.
Annotation des mains et du visage
Cette annotation permet d'indiquer quelles sont les coordonnées des mains et du visage du locuteur dans chaque image des vidéos. Elle concerne les 25 locuteurs du corpus CLeLfPC, version 8, déposée sous licence CC-By-NC-4.0 sur https://www.ortolang.fr.
Des phonèmes aux clés (QUOI ?)
Système prédictif des séquences de clés (français)
Le système de prédiction automatique des clés à partir d'un fichier audio et de sa transcription, pour la langue française, est disponible à partir de la version 4.10 de SPPAS.
Synchronisation main/son (QUAND ?)
Système prédictif des moments de transition de positions
Le système de prédiction automatique des moments de transitions de la main d'une voyelle à l'autre est disponible à partir de la version 4.17 de SPPAS.
Analyse des moments de transition de positions
Etude des moments de transition de positions observés dans les annotations du corpus CLeLfPC : analyse de la désynchronisation entre la position de la main et la réalisation acoustique correspondante.
Trajectoire de la main (OU ?)
Angle de la main
Ce livrable s'attache à décrire les différents modèles d'angles de la main implémentés et une étude des valeurs d'angles observées dans des données annotées de CLeLfPC.
Coordonnées des positions des voyelles
Ce livrable s'attache à décrire les différents modèles implémentés pour déterminer les coordonnées des voyelles sur le visage détecté, et propose une étude des valeurs observées dans des données annotées de CLeLfPC.
Création de ressources
Enregistrements et annotations en lecture de textes
Les premières étapes du processus de création des capsules : sélection du contenu textuel à enregistrer, modalités d'enregistrement, annotations manuelles et codage automatique de SPPAS.