- (0) neutre
- (1) /p/, /d/, /Z/
- (2) /k/, /v/, /z/
- (3) /s/, /R/
- (4) /b/, /n/, /H/
- (5) /m/, /t/, /f/, absence de consonne
- (6) /l/, /S/, /J/, /w/
- (7) /g/
- (8) /j/, /N/
Livrable WP2 - L1 : Système prédictif des séquences de clés (français)
Objectif
Dans le cadre de la création d’un système de génération automatique du codage, la première étape requise consiste à déterminer la séquence de clés à produire à partir de la séquence des phonèmes qui ont été prononcés.
Afin de répondre à cet objectif, il est nécessaire de disposer en amont d’un système qui permet d’obtenir la séquence de phonèmes à partir d’un texte, qui peut être un texte écrit ou la transcription orthographique d’un enregistrement de parole. Ce système, déjà existant dans SPPAS doit être vérifié pour son utilisation spécifique dans le cadre de ce projet.
Le système de prédiction des clés est ensuite développé, associé un à fichier de règles spécifique à une langue donnée.
Description du système de conversion texte - clés
1. Liste des phonèmes du système
La chaîne des traitements qui permettent d'obtenir les sons prononcés a été vérifiée et nous avons apporté les modifications nécessaires pour son fonctionnement avec la LfPC. Par exemple, il a fallu modifier le dictionnaire de prononciation, c'est-à-dire la ressource linguistique qui contient les prononciations possibles des mots de la langue. En l'occurrence, l'inventaire phonologique n'était pas adapté.
C.f. Chapitre 2 du document « SPPAS Resources »
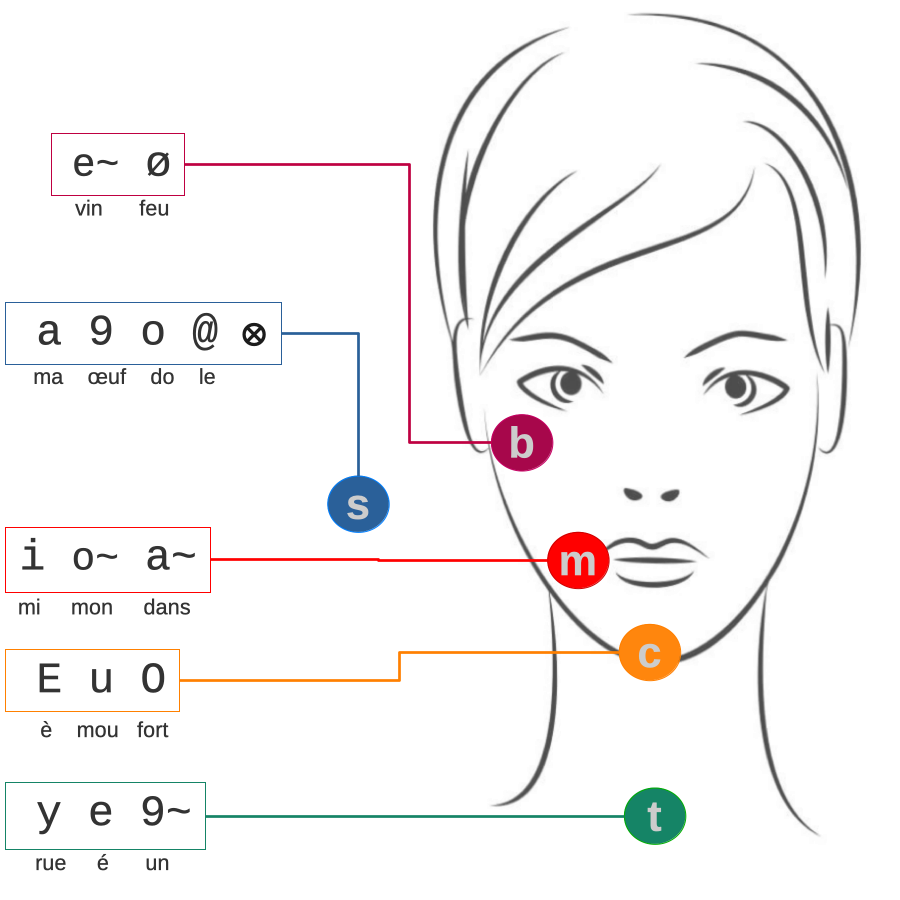
2. Proposition d’une dénomination des clés
Pour produire un codage des clés LfPC, il est nécessaire d’introduire une dénomination à
chacune des formes de la main et des positions de la main. Le codage que nous avons proposé
repose sur ceux déjà existants pour la langue française et la langue anglaise. Nous avons
ajouté une dénomination pour la position et la forme neutre (pas de parole prononcée).
Les formes de la main sont ainsi numérotées de 0 à 8. Les positions de la main sont nommées :
‘s’, ‘m’, ‘c’, ou ‘t’ comme pour le codage anglais, auquel nous avons ajouté ‘b’ et ‘n’.

3. Fonctionnement du système de prédiction des clés
La structure de la LfPC suppose qu’une clé est représentée par une combinaison consonne-voyelle en une forme de main (C) et une position spécifiée (V). Chaque phonème d’une séquence est alors transformé automatiquement selon sa classe donc étiqueté avec C ou V. Compte tenu de la séquence d’étiquettes de classes, l’algorithme spécifie une séquence de paires de position de la main selon les règles du codage. Des règles spécifiques sont mises en œuvre pour les combinaisons de classes atypiques telles que VC, C, CC et CVC, au lieu du ‘CV’ habituel.
Lorsque la séquence d’étiquettes de classe est segmentée, elle est re-transformée en une séquence de phonèmes. Chaque étiquette de phonème est ensuite associée à son code clé selon la dénomination indiquée précédemment.
4. Exemple de conversion texte-clés
4.1 Phrase écrite
A partir de la phrase « un demi pot d’huile de coco »
le système produira la séquence de clés :
5-t.1-s.5-m.1-s.1-s.4-m.6-s.1-s.2-s.2-s.
Dans cette dénomination, le "." sépare les clés tandis que le "-" sépare
la forme de la position.
4.2 Phrase lue
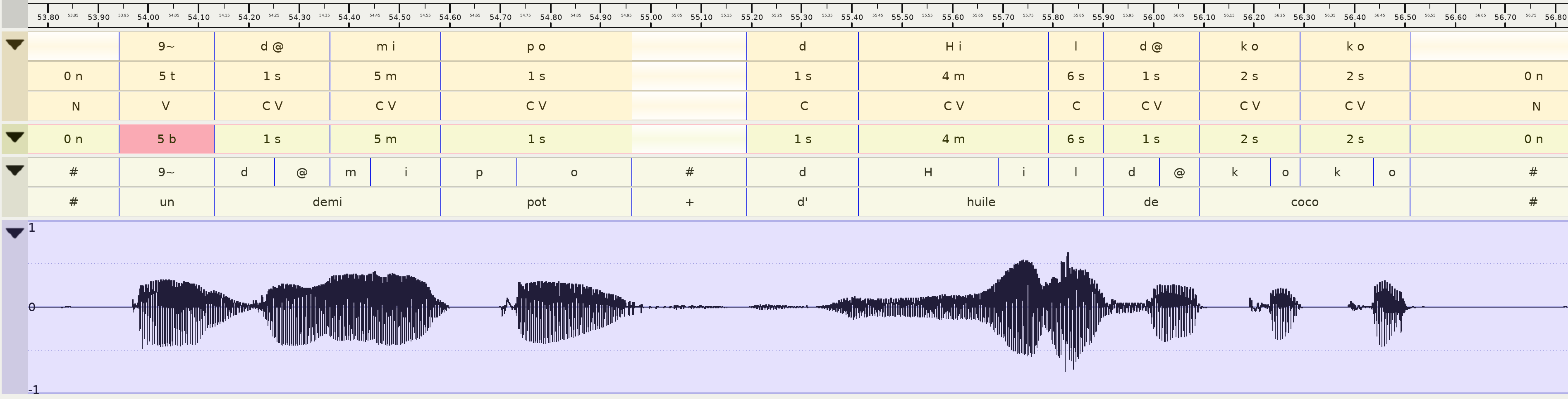
Lorsque cette même phrase a été lue, les mots et les phonèmes sont alignés automatiquement sur le signal audio par SPPAS (lignes 5 et 6 de la figure ci-dessous). Il en va donc de même pour la séquence produite. Dans l’exemple ci-après, les 3 premières lignes correspondent au résultat produit par le système, et la 4ème la correction manuelle après observation de ce qui a été réellement produit par la personne qui avait codé la phrase.
Accès et utilisation du système
1. Généralités
La version stable de ce système est distribuée sous les termes de la licence GNU GPL v3. Elle fait partie du logiciel SPPAS, depuis la version 4.10, et peut être téléchargée à l’adresse : https://sppas.org.
SPPAS procède en plusieurs étapes ; de cette manière, chaque résultat intermédiaire peut être vérifié et corrigé avant de passer à l’étape suivante.
Etape 1 : la normalisation du texte
Elle permet de supprimer les majuscules et la ponctuation, d’écrire les nombres en toutes lettres (« 2 » devient « deux »), de segmenter en mots, etc.
Par exemple, la phrase :
L’abat-jour est cassé parce qu’il est tombé 2-3 fois.
sera normalisée :
l’ abat-jour est cassé parce_qu’ il est tombé deux trois fois
Dans cet exemple, les mots sont séparés par des espaces.
Etape 2 : la phonétisation
Elle permet de convertir le texte normalisé en phonèmes... Mais parfois, un mot peut avoir plusieurs prononciations. La phrase d’exemple ci-dessus sera phonétisée :
l A/-b-A/-Z-u-R E|e|E-t|E-s-t k-A/-s-e p-A/-R-s-@-k|p-A/-R-s-k i-l E|e|E-t|E-s-t t-O~-b-e d-2|d-2-z t-R-w-A/|t-R-w-A/-z f-w-A/|f-w-A/-z
Les espaces sont utilisés pour séparer les mots, les tirets pour séparer les phonèmes, et la barre verticale pour séparer les différentes prononciations d'un même mot.
Etape 3 : l’alignement
Il permet de mettre en correspondance un enregistrement audio avec les phonèmes. Lorsque c’est nécessaire, l’aligneur va aussi choisir la prononciation d’un mot parmi les différentes possibilités.
Dans le cas d’un texte, il n’y a pas d’enregistrement audio ; le système choisira la prononciation la plus courte, selon le principe d'économie. Aucune liaison ne sera donc phonétisée, comme on le voit dans l'exemple :
0.0 0.02 l
0.03 0.05 A/
0.06 0.08 b
0.09 0.11 A/
0.12 0.14 Z
0.15 0.17 u
0.18 0.2 R
0.21 0.23 E
0.24 0.26 k
0.27 0.29 A/
0.3 0.32 s
0.33 0.35 e
0.36 0.38 p
0.39 0.41 A/
0.42 0.44 R
0.45 0.47 s
0.48 0.5 k
0.51 0.53 i
0.54 0.56 l
0.57 0.59 E
0.6 0.62 t
0.63 0.65 O~
0.66 0.68 b
0.69 0.71 e
0.72 0.74 d
0.75 0.77 2
0.78 0.8 t
0.81 0.83 R
0.84 0.86 w
0.87 0.89 A/
0.9 0.92 f
0.93 0.95 w
0.96 0.98 A/
On remarque ici que le mot « est » a été phonétisé /E/ plutôt que /e/. Effectivement, comme il n’y a pas de fichier audio, le système utilise la première variante dans le dictionnaire. Ainsi, modifier le dictionnaire permet d’obtenir la variante souhaitée.
Etape 4 : le codage LfPC
Le système de conversion développé dans le cadre de ce projet est alors appliqué sur la séquence de phonèmes. Il permet d’obtenir la séquence de codage des clés, comme pour l'exemple :
6-s.4-s.1-c.3-c.2-s.3-t.1-s.3-s.3-s.2-m.6-c.5-m.4-t.1-b.5-s.3-s.6-s.5-s.6-s
2. Tester le système en ligne
Bien que ce n'était pas initialement prévu dans le projet, nous avons implémenté une interface qui permet d'utiliser ce système en ligne. Ce lien permet de tester en ligne le système sur du texte écrit. En revanche, pour obtenir la séquence de clés à produire à partir d'un enregistrement audio, il faut télécharger et installer le logiciel SPPAS.
3. Quelles étapes faut-il réaliser ?
D’abord, il faut préparer les données. Il faut, en effet, commencer par préparer un
petit texte dans un fichier .txt, et/ou
s’enregistrer avec un dictaphone ou un ordinateur pour obtenir un fichier audio
non compressé (.wav ou .aif). Attention, il n'est pas possible d'utiliser un smartphone,
car il ne permet pas d'obtenir ce type de fichier. L'enregistrement devra ensuite être transcrit.
Vous pouvez consulter la documentation de SPPAS pour plus de détails à propos de la
transcription orthographique.
Ensuite, SPPAS génère le résultat ! L’utilisation de SPPAS permettra d’obtenir la séquence de clés qui correspond au texte et/ou à l’enregistrement.
4. Comment l’utiliser ?
Pour les utilisateurs débutants, ce résultat peut être obtenu en créant un fichier texte, avec
l’extension .txt, et en utilisant l’interface graphique de SPPAS.
Pour les utilisateurs avancés, ce résultat peut être obtenu avec la commande Unix suivante :
echo "L’abat-jour est cassé parce qu’il est tombé 2-3 fois." |
.sppaspyenv~/bin/python ./sppas/bin/normalize.py -r ./resources/vocab/fra.vocab |
.sppaspyenv~/bin/python ./sppas/bin/phonetize.py -r ./resources/dict/fre.dict |
.sppaspyenv~/bin/python ./sppas/bin/alignment.py |
.sppaspyenv~/bin/python ./sppas/bin/cuedspeech.py -r resources/cuedspeech/cueConfig-fra.txt
Pour aller plus loin...
Configuration du système des règles
Les règles du système permettent de définir l’ensemble des connaissances et contraintes du
codage d’une langue. Ces règles sont écrites dans un fichier texte qui peut facilement être
modifié par un utilisateur. Il se trouve dans le package du logiciel, dans le dossier :
resources/cuedspeech/cueConfig-fra.txt.
Dans un premier temps, ce fichier contient la liste des phonèmes et leur associe une classe, C ou V de la manière suivante :
PHONCLASS 9 V
PHONCLASS E V
PHONCLASS l C
PHONCLASS R C
Le fichier indique ensuite la forme de la main de chaque consonne et la position de la main de chaque voyelle, comme ceci :
PHONKEY 9 s
PHONKEY E c
PHONKEY l 6
PHONKEY R 3
Enfin, le fichier indique la forme de la main en cas d’absence de consonne (clé –V) et la position de la main en cas d’absence de voyelle (clé C-) :
PHONKEY cnil 5
PHONKEY vnil s
En savoir plus...
Brigitte Bigi (2023). An analysis of produced versus predicted French Cued Speech keys. In 10th Language & Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics, Poznań, Poland, pages 24-28, hal-04081282.
Contributeurs
Développement logiciel : Brigitte Bigi (LPL)
Expertise du codage : Maryvonne Zimmermann (Datha)
Validation du système : acteurs de terrain (ALPC)
À propos
- Rédaction du document : Brigitte Bigi
- Licence du document : GNU documentation libre - FDL 1.3
- Copyright 2023 Brigitte Bigi, CNRS, Laboratoire Parole et Langage, France
- URL de ce document : https://auto-cuedspeech.org/wp2l1.html
- Dernière mise à jour : septembre 2023