Livrable WP4 - L2 : Position des voyelles
Introduction
Objectifs
Dans le cadre du développement d'un système de génération automatique du codage, la troisième étape consiste à modéliser la trajectoire de la main. Cette modélisation repose sur la prédiction de sa position, de son angle et de sa taille par rapport au visage du locuteur, image par image, dans la vidéo. Ce livrable porte sur l'étude de la position des voyelles et leur implémentation dans le système SPPAS.
Approche globale
Dans un premier temps, des experts ont défini les positions des voyelles en fonction d'un visage théorique. Ces positions ont ensuite été exprimées en fonction des 68 points de repère faciaux extraits grâce au système de détection Face landmarks de SPPAS.
Aucune variabilité n'a été introduite dans l'estimation de ces coordonnées. Lorsqu’une position doit être atteinte, l’extrémité du doigt cible (index ou majeur, selon la forme de la main) est directement assignée aux coordonnées préétablies dans l'image correspondante. De même, la taille de la main est toujours proportionnelle à la hauteur du visage et reste constante. La trajectoire suivie entre ces positions est une ligne droite à vitesse constante. En revanche, différents modèles d’angle ont été implémentés (voir WP4 - L1).
Ce livrable analyse les coordonnées observées dans des données annotées et décrit les modèles proposés pas SPPAS.
Nomenclatures
Dans ce document, les coordonnées dans le plan 2D sont exprimées selon les axes des abcisses x et ordonnées y, comme cela est conventionnellement fait dans une image :
|---------------------> x
|
|
|
\/
y
Le visage du locuteur est représenté par un ensemble de 68 points dont les coordonnées sont obtenues automatiquement avec SPPAS en utilisant successivement les annotations "Face detection", "Face Identity" et "Face landmarks", comme illustré ci-dessous :

Dans la suite de ce document, nous utilisons la nomenclature suivante pour désigner les différentes positions des voyelles :
- pommette : "b" (cheekbone), voyelles : [2], [e~]
- menton : "c" (chin), voyelles : [E], [O], [u]
- bouche : "m" (mouth), voyelles : [i], [a~], [O~]
- côté du visage : (side), voyelles : [a], [@], [9], [o]
- gorge : (throat), voyelles : [y], [e], [9~]
Il est à noter que la position neutre, utilisée lorsque les codeurs ne parlent pas, ne fait pas partie de cette étude.
Image de référence
Une image de référence d'un visage "neutre" a été créée afin d'y reporter les coordonnées observées, de les rendre comparables et de les analyser. Il s'agit d'une image de 1000x1000 pixels, sur laquelle sont placés les 68 points de repère du "Face landmarks". Ces coordonnées permettent de situer précisément les points de repère du visage, comme illustré ci-dessous :
| Index | x | y |
|---|---|---|
| 0 | 0 | 165 |
| 1 | 2 | 300 |
| 2 | 15 | 435 |
| 3 | 40 | 570 |
| 4 | 90 | 695 |
| 5 | 170 | 805 |
| 6 | 260 | 905 |
| 7 | 375 | 980 |
| 8 | 500 | 1000 |
| 9 | 625 | 980 |
| 10 | 760 | 905 |
| 11 | 830 | 805 |
| 12 | 910 | 695 |
| 13 | 960 | 570 |
| 14 | 985 | 435 |
| 15 | 998 | 300 |
| 16 | 1000 | 165 |
| 17 | 99 | 70 |
| 18 | 170 | 15 |
| 19 | 250 | 0 |
| 20 | 330 | 20 |
| 21 | 410 | 55 |
| 22 | 590 | 55 |
| 23 | 680 | 20 |
| 24 | 750 | 0 |
| 25 | 820 | 15 |
| 26 | 910 | 70 |
| 27 | 500 | 150 |
| 28 | 500 | 240 |
| 29 | 500 | 330 |
| 30 | 500 | 420 |
| 31 | 390 | 480 |
| 32 | 445 | 500 |
| 33 | 500 | 510 |
| 34 | 555 | 500 |
| 35 | 620 | 480 |
| 36 | 200 | 160 |
| 37 | 255 | 132 |
| 38 | 315 | 132 |
| 39 | 370 | 170 |
| 40 | 255 | 185 |
| 41 | 315 | 185 |
| 42 | 630 | 170 |
| 43 | 685 | 132 |
| 44 | 745 | 132 |
| 45 | 800 | 160 |
| 46 | 745 | 185 |
| 47 | 685 | 185 |
| 48 | 302 | 633 |
| 49 | 375 | 610 |
| 50 | 445 | 600 |
| 51 | 500 | 605 |
| 52 | 555 | 600 |
| 53 | 625 | 610 |
| 54 | 698 | 633 |
| 55 | 625 | 705 |
| 56 | 555 | 745 |
| 57 | 500 | 750 |
| 58 | 445 | 745 |
| 59 | 375 | 705 |
| 60 | 328 | 635 |
| 61 | 445 | 645 |
| 62 | 500 | 650 |
| 63 | 555 | 645 |
| 64 | 672 | 635 |
| 65 | 555 | 677 |
| 66 | 500 | 682 |
| 67 | 445 | 677 |

Données utilisées pour l'étude
Pour plus d’informations sur les annotations effectuées, voir le livrable WP1 - L4 de ce projet. En résumé, les transitions de position des quatre sessions impliquant cinq locutrices-codeuses ont été annotées manuellement. De plus, pour chaque vidéo du corpus, nous avons automatiquement extrait :
- les 68 points de référence du visage,
- les 21 points de référence de la main (voir WP4 - L1).
Etat de l'art
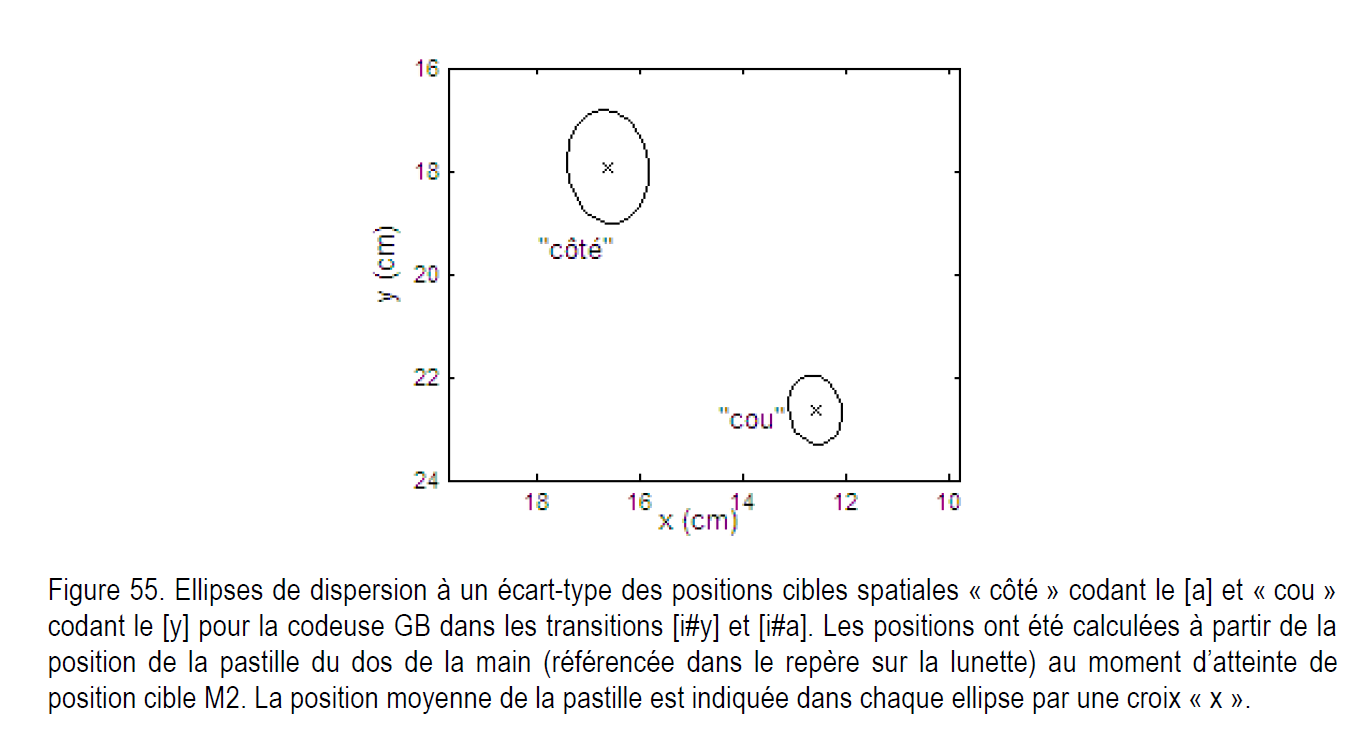
Dans la thèse de V. Attina (2005), le recueil du corpus a été effectué en collant des pastilles sur la main codeuse et sur le visage afin de servir de repères pour l'analyse des positions des voyelles. Nous reportons ci-après la figure représentant la capture et la figure obtenue pour l'analyse. Il est dit dans cette thèse : "Nous pouvons voir sur la Figure 55 les ellipses de dispersion des positions cibles pour les deux types de transition [i#y] et [i#a]. La position « côté » du [a], qui n’a pas de support fixe sur le visage, est beaucoup plus dispersée que la position « cou » du [y]."

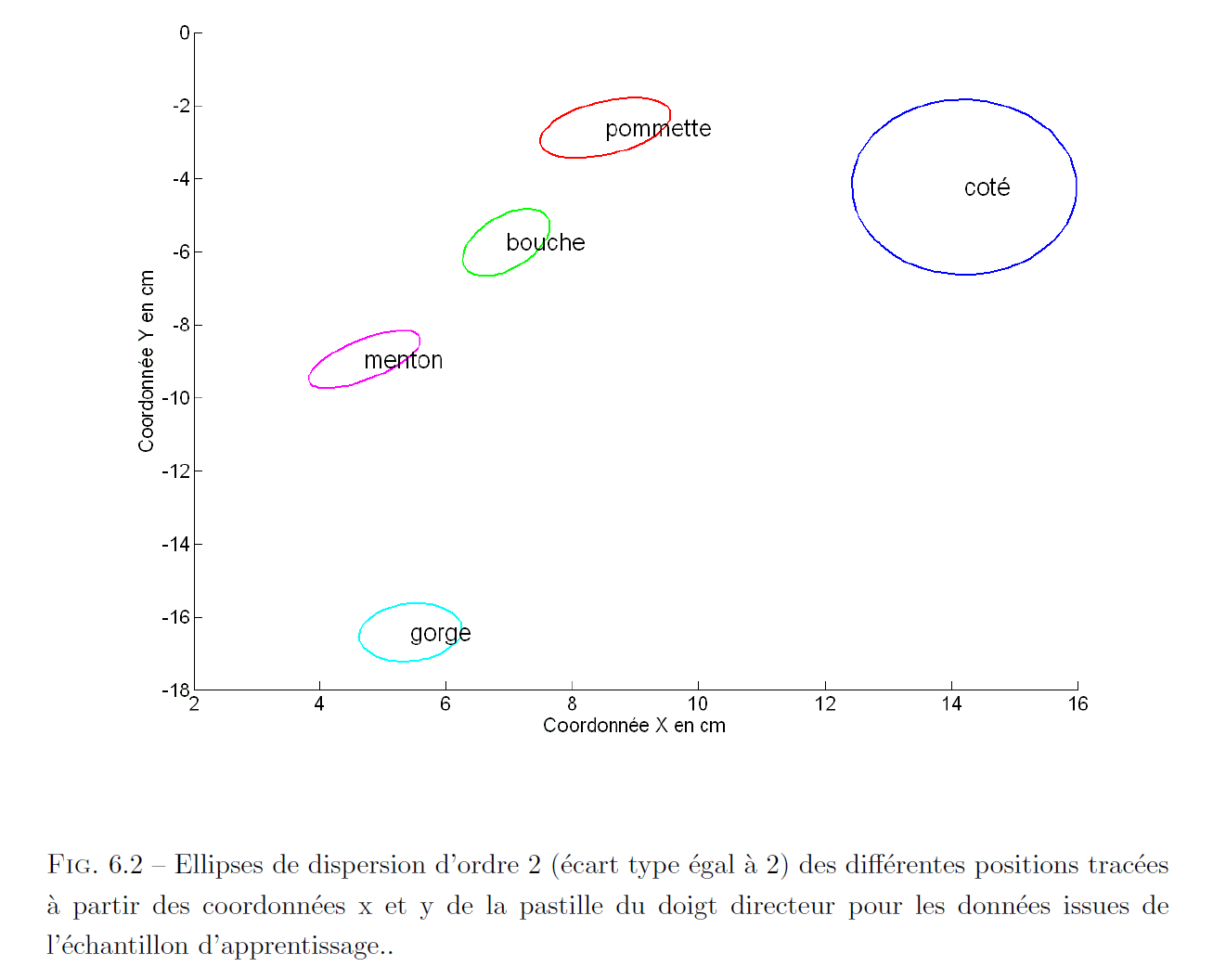
N. Aboutabit (2008) a étendu ce travail d'analyse des positions des voyelles dans le but de créer un système de classification automatique. Il a obtenu les positions illustrées par la figure que nous reportons ci-après (à noter : les positions correspondent à un codage de la main gauche), sans en effectuer d'analyse.
Différents modèles des positions des voyelles
Modèle 1 : positions théoriques
Description
Les positions de ce modèle ont été établies en s'appuyant sur l'illustration des clés du code de l'ALPC . Les positions des voyelles de cette illustration ont ensuite été reportées sur l'image du visage de référence. Nous avons ainsi obtenu les coordonnées des positions qui ont ensuite été exprimées relativement aux 68 points de repères faciaux. De cette manière, ces positions peuvent être justement estimées sur des visages de forme et de taille différentes de celle de référence.
Jusqu'à la version 4.24 de SPPAS, ces coordonnées correspondaient à celles du système prototype (c.f. article publié à la conférence JEP'24). Ces valeurs ont ensuite été vérifiées et ajustées, notamment pour la bouche, car les experts avaient noté des erreurs de placement dans les vidéos générées.
Positions des voyelles
Position 'm'
Cette position se situe près du coin de la bouche. Pour l'axe des abscisses (x), la distance entre le point cible et la bouche doit tenir compte de l'orientation gauche/droite du visage. Cela est fait en utilisant un point du bord du visage (x4). Il faut aussi tenir compte de l'ouverture (largeur) de la bouche, ce qui est fait en utilisant le point le plus à droite (x48). Pour les ordonnées, il faut simplement tenir compte de la position de la bouche dans le visage et de son ouverture (en hauteur), ce qui peut être fait avec un seul point (y60).
Position 'b'
Cette position est située sur la pommette. L'axe des abscisses (x) est calculé à partir d'un point du bord du visage (x4) et du coin de l'oeil (x36), pour garantir un positionnement stable en cas d'orientation gauche/droite du visage. L'axe des ordonnées (y) est basé sur les bords du visage pour éviter une trop grande variation verticale.
Position 'c'
Cette position correspond au menton. L'axe des abscisses (x) est directement donné par le centre du menton. L'axe des ordonnées (y) est ajusté en fonction de la distance entre le menton et la bouche, ce qui permet d'avoir une position cohérente indépendamment de la taille de la mâchoire.
Position 's'
Cette position est située sur le côté du visage. L'axe des abscisses (x) est déterminé à partir du bord du visage, avec une correction basée sur sa largeur. L'axe des ordonnées (y) prend en compte la hauteur du visage entre le point de référence de la mâchoire et un point légèrement plus bas, pour obtenir une position stable lors d'une inclinaison du visage.
Position 't'
Cette position correspond à la gorge, à la pomme d'Adam. L'axe des abscisses (x) est directement donné par le centre du menton. L'axe des ordonnées (y) est calculé à partir de la distance entre le menton et la bouche, de manière à garder une cohérence avec la morphologie du visage, et/ou une inclinaison du visage vers le bas.

Synthèse du modèle 1
Ce premier modèle de positionnement des voyelles dans le cadre de la Langue française Parlée Complétée (LfPC) repose sur une approche théorique, s'inspirant directement de l'illustration des clés du code fournie par l'ALPC. L'objectif principal est de proposer un cadre de référence stable et adaptable, permettant de positionner les voyelles de manière cohérente sur différents visages, indépendamment de leur forme ou de leur taille.
L'utilisation des 68 points de repère faciaux fournis par SPPAS est cruciale pour atteindre cet objectif. Ces points permettent de définir une géométrie faciale précise, servant de base au calcul des coordonnées des voyelles. En exprimant les positions des voyelles relativement à ces points de repère, nous nous assurons que le modèle s'adapte dynamiquement aux variations individuelles des visages.
Les formules de calcul des positions des voyelles, bien que basées sur des observations théoriques, ont été conçues pour être robustes et intuitives. Elles prennent en compte des éléments clés de la morphologie faciale, tels que la position et la largeur de la bouche, la distance entre les yeux et le menton, ou encore la hauteur du visage. Cette approche permet de minimiser les variations dues aux différences de morphologie et d'assurer une certaine stabilité dans le positionnement des voyelles. Cependant, il est important de noter que ce modèle théorique présente certaines limitations. Les positions des voyelles sont basées sur une interprétation visuelle de l'illustration de l'ALPC, qui peut être subjective. Dans les versions antérieures de SPPAS, ce modèle a servi de base au système prototype, mais des ajustements ont été nécessaires suite aux retours d'experts. Ces ajustements, notamment pour la position de la bouche, soulignent l'importance de confronter le modèle théorique à des données empiriques et de l'affiner en conséquence.
Modèle 2 : faible variation
Après visionnage des vidéos générées par le premier modèle, les experts du projet ont proposé les ajustements suivants des positions, par rapport au modèle 1 :
Les ajustements apportés par les experts au modèle 1 se concentrent sur les positions 'b' (pommette) et 's' (côté du visage), car ces positions étaient les plus problématiques dans le modèle initial. L'ajustement de l'axe des abscisses (xb) réduit la distance entre le point de la pommette et le bord du visage. Les experts ont également jugé que la position verticale de ces voyelles étaient trop haute. En résumé, le modèle 2 représente une version affinée du modèle 1, intégrant les retours d'expérience des experts pour améliorer la précision du positionnement des voyelles.
Nous avons également défini une "zone acceptable" plus ou moins étendue selon la position, bien qu'elle ne soit pas utilisée par SPPAS.
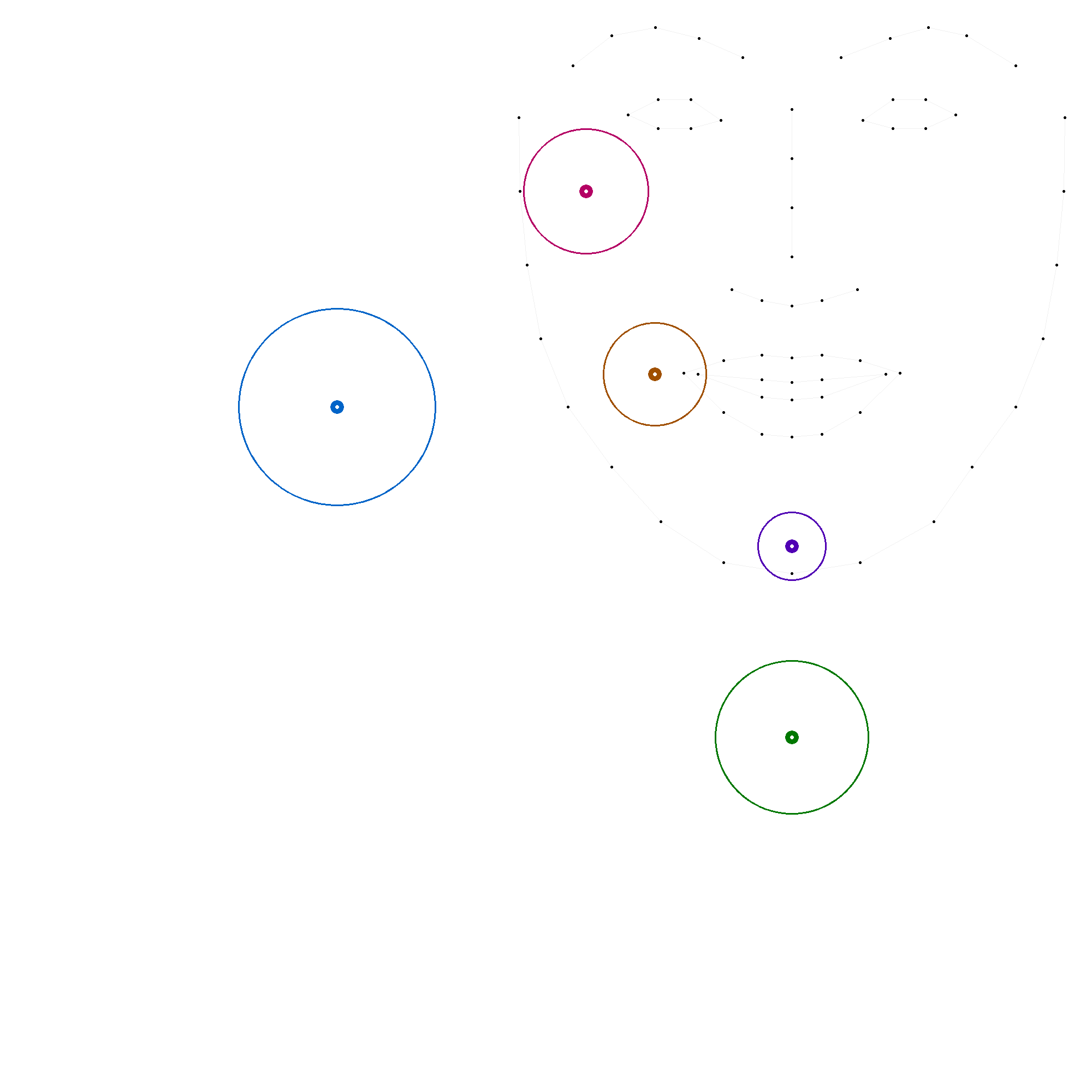
Modèle 3 : coordonnées mesurées dans un échantillon
Comme pour le modèle 3 de l'angle de la main, les coordonnées de ce modèle ont été établies en sélectionnant des images extraites des vidéos du corpus CLeLfPC. Trois images par position, représentant différentes codeuses et différentes formes de la main, ont été sélectionnées par les experts du projet.
Comme pour le modèle 1, les coordonnées ont été manuellement transposées en calcul relatif par rapport aux points du visage de référence. La valeur retenue est la moyenne (arrondie). Les valeurs relevées puis transposées sont indiquées dans le tableau ci-après.
| Forme | Position | x | y |
|---|---|---|---|
| 1 | b | 64 | 375 |
| 2 | b | 141 | 425 |
| 6 | b | 60 | 370 |
| 7 | b | 145 | 339 |
| 8 | b | -15 | 397 |
| 3 | c | 349 | 836 |
| 4 | c | 461 | 967 |
| 5 | c | 393 | 944 |
| 6 | c | 499 | 927 |
| 7 | c | 488 | 904 |
| 1 | m | 309 | 710 |
| 4 | m | 215 | 742 |
| 5 | m | 233 | 653 |
| 6 | m | 213 | 656 |
| 8 | m | 304 | 713 |
| 2 | s | -337 | 753 |
| 3 | s | -622 | 726 |
| 4 | s | -453 | 667 |
| 6 | s | -331 | 774 |
| 7 | s | -415 | 370 |
| 1 | t | 543 | 1429 |
| 3 | t | 339 | 1305 |
| 4 | t | 505 | 1382 |
| 5 | t | 448 | 1272 |
| 6 | t | 434 | 1573 |
Ces valeurs permettent d'obtenir les coordonnées (x,y) moyennes, les écart-types ci-dessous :
- b : moyenne (79, 381), écart-type (66, 32)
- c : moyenne (438, 916), écart-type (65, 50)
- m : moyenne (255, 695), écart-type (48, 39)
- s : moyenne (-432, 658), écart-type (118, 166)
- t : moyenne (454, 1392), écart-type (78, 119)
Le modèle 3 s'appuie ainsi sur des mesures directes effectuées sur un échantillon d'images sélectionnées du corpus CLeLfPC, offrant une perspective empirique par rapport aux modèles théoriques précédents. Les coordonnées moyennes obtenues à partir de cet échantillon révèlent des différences notables par rapport au modèle 2, affiné par les experts.
La position 'b' (pommette) est globalement plus éloignée du centre du visage en abcisses tandis que la hauteur est abaissée par rapport à celle du modèle 2. La position 'c' (menton) est un peu plus haute et plus excentrée par rapport au modèle 2. La position 'm' (bouche) est légèrement plus basse que dans le modèle 2. La position 's' (côté du visage) quant à elle est significativement plus éloignée du visage, et un peu plus haute. Enfin, la position 't' (gorge) s'avère plus basse que dans le modèle 2, se rapprochant de la pomme d'Adam.
En résumé, le modèle 3, basé sur des observations empiriques, tend à placer les voyelles plus basses, à l'exception de la position 's', qui est plus haute. Ces différences soulignent l'écart potentiel entre les modèles théoriques ou ajustés par des experts et les données issues d'observations directes, quand bien même celles-ci ont été sélectionnées par les experts.
Résultats des modèles 1 à 3
Exemples de vidéos codés
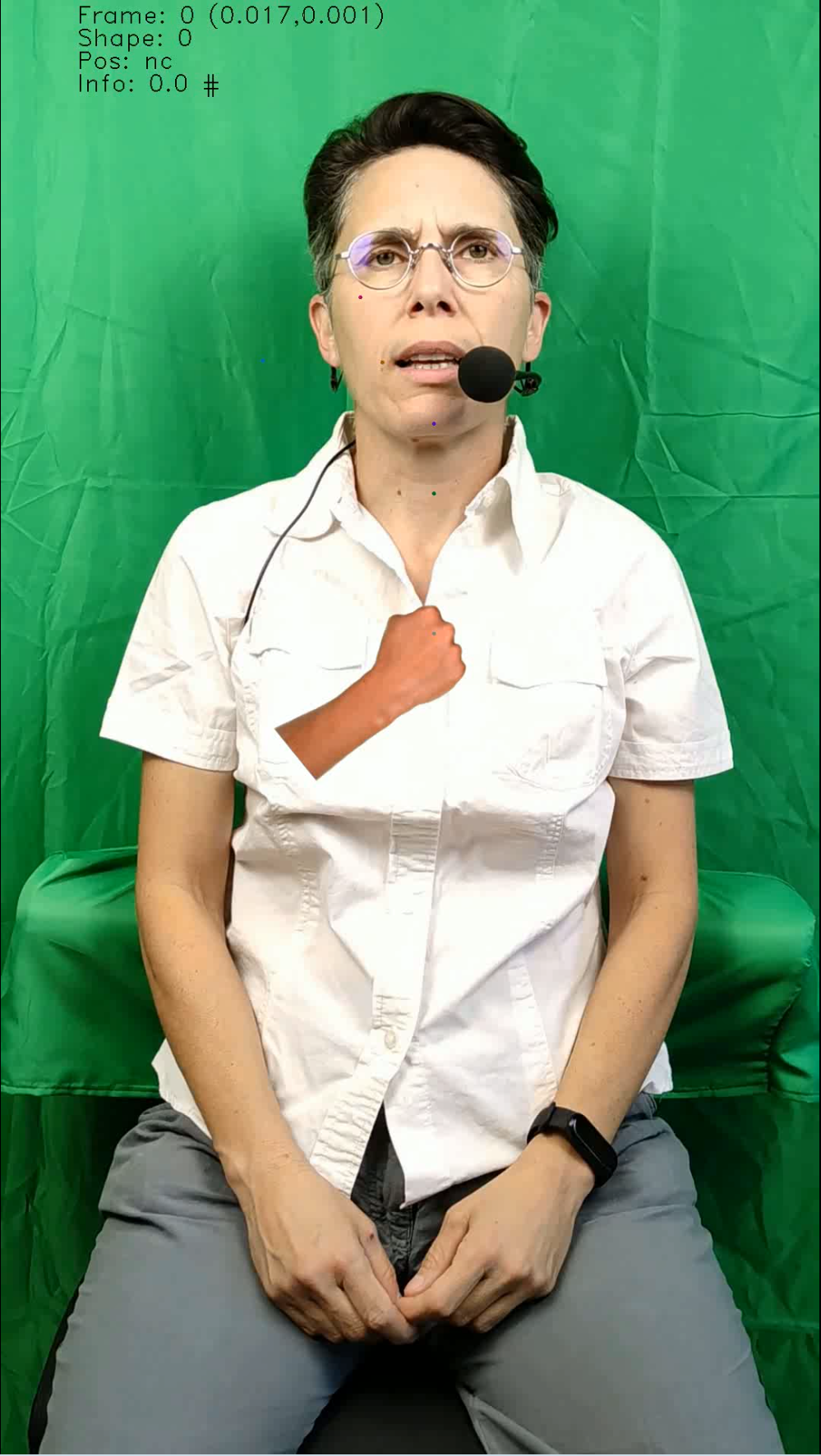
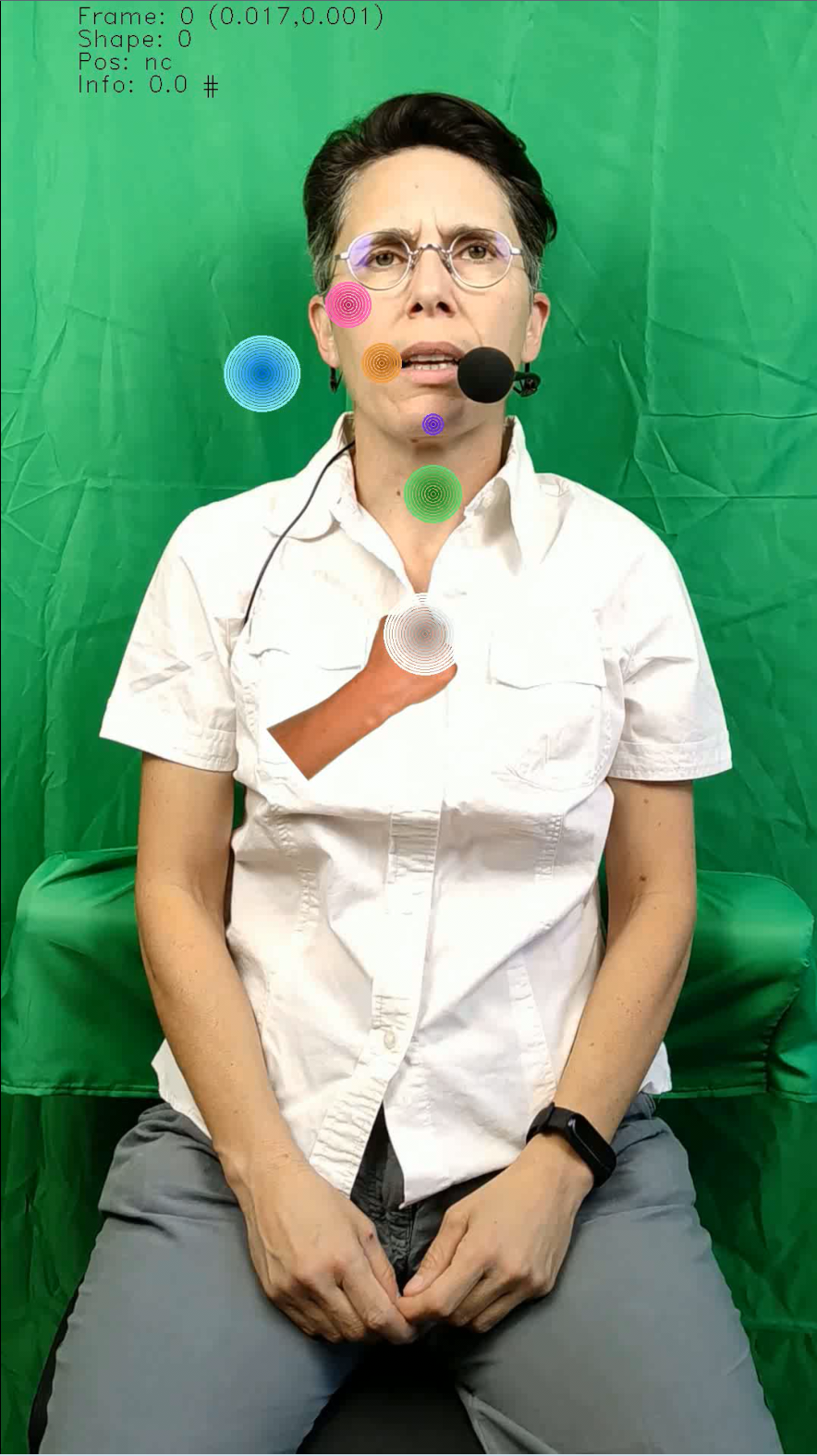
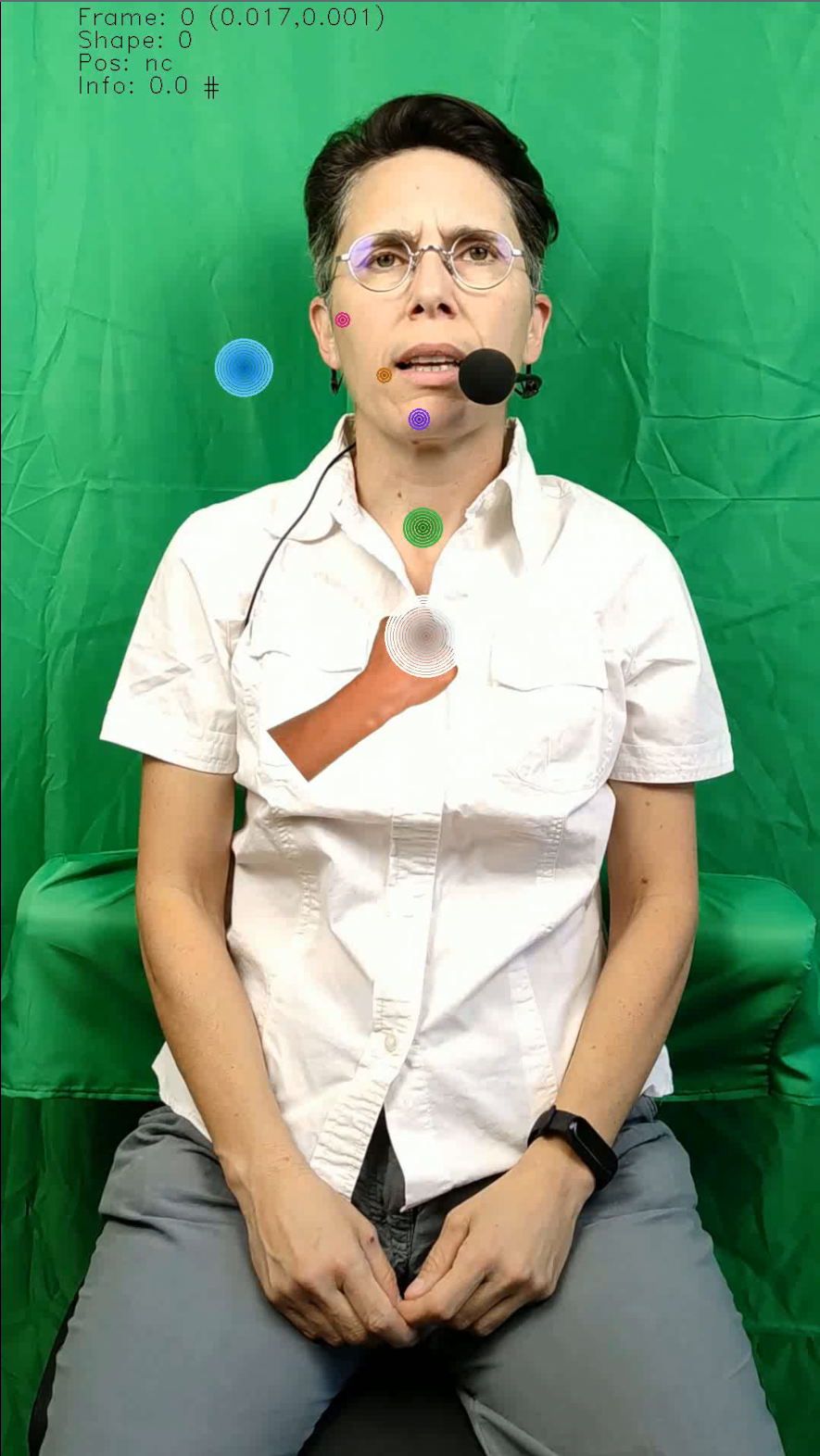
Analyse des positions observées dans le corpus
Nous avons collecté et analysé un grand nombre de données pour déterminer comment les codeurs indiquent les voyelles. Nous avons extrait 3769 valeurs et, après avoir filtré les données aberrantes, nous avons conservé 3752 valeurs pour notre analyse.
Statistiques sur l'ensemble des données
| Position | Nombre | Moyenne | Écart-type |
|---|---|---|---|
| b | 230 | (144, 397) | (70, 92) |
| c | 529 | (425, 888) | (112, 76) |
| m | 676 | (260, 682) | (79, 91) |
| s | 1750 | (-193, 635) | (241, 233) |
| t | 584 | (435, 1419) | (143, 223) |
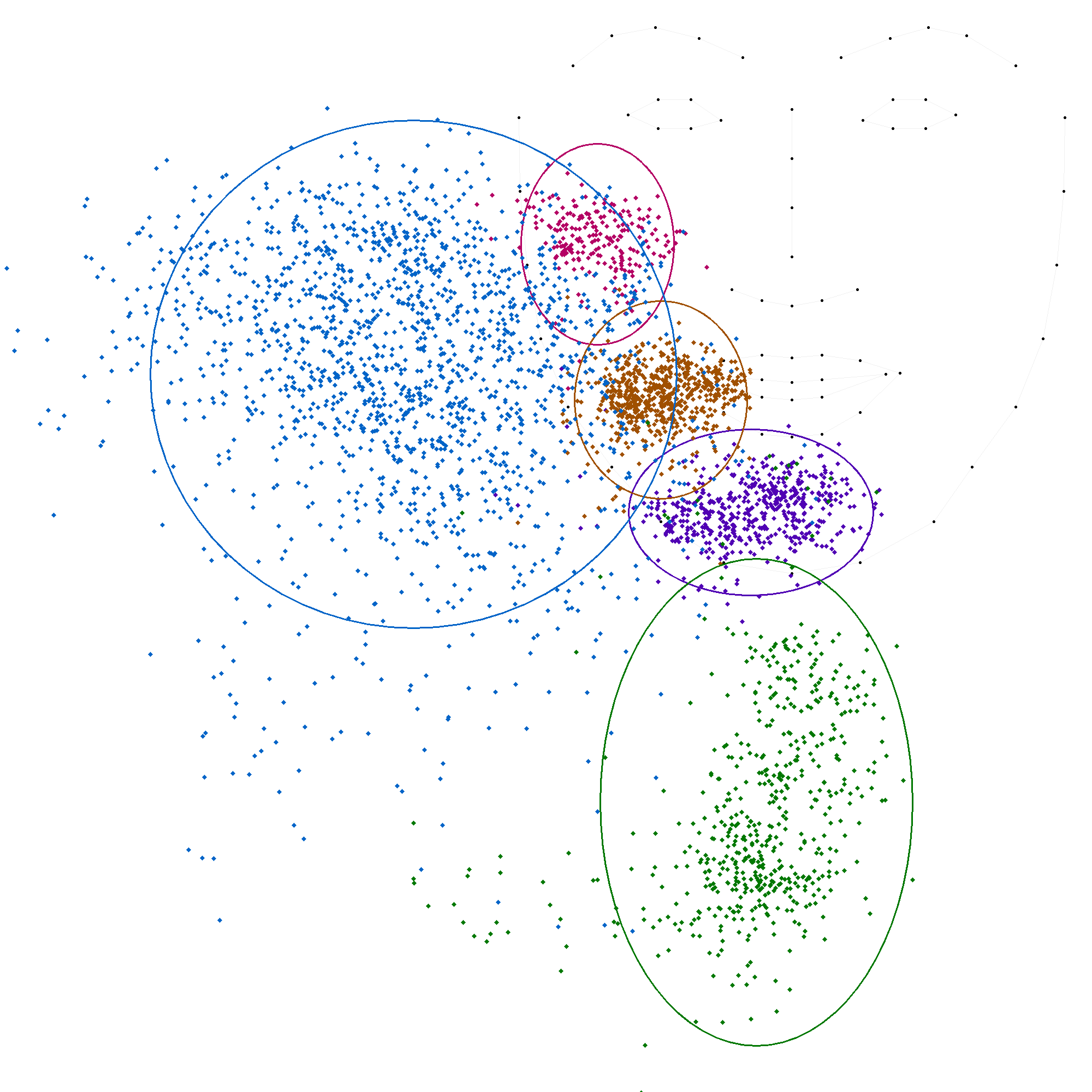
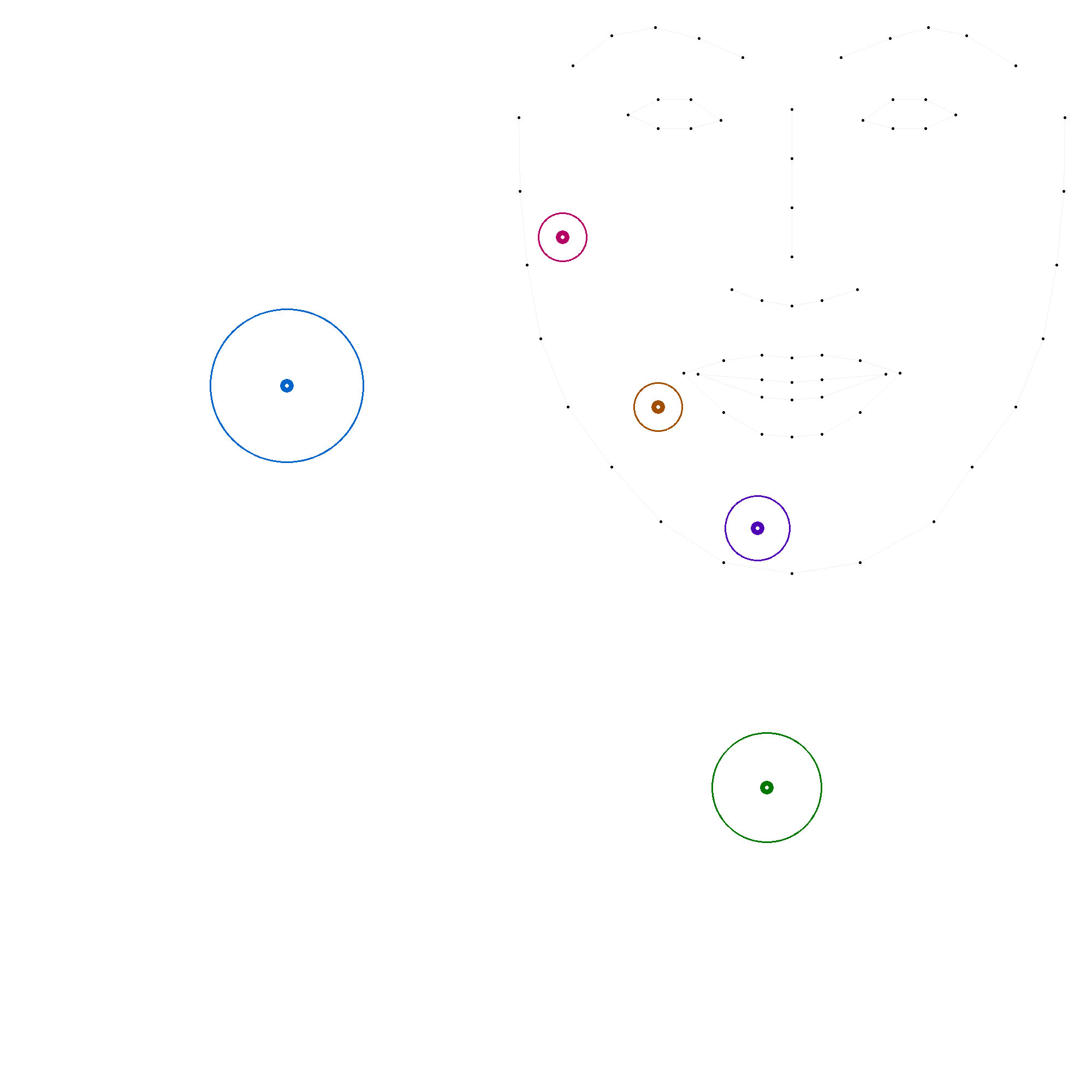
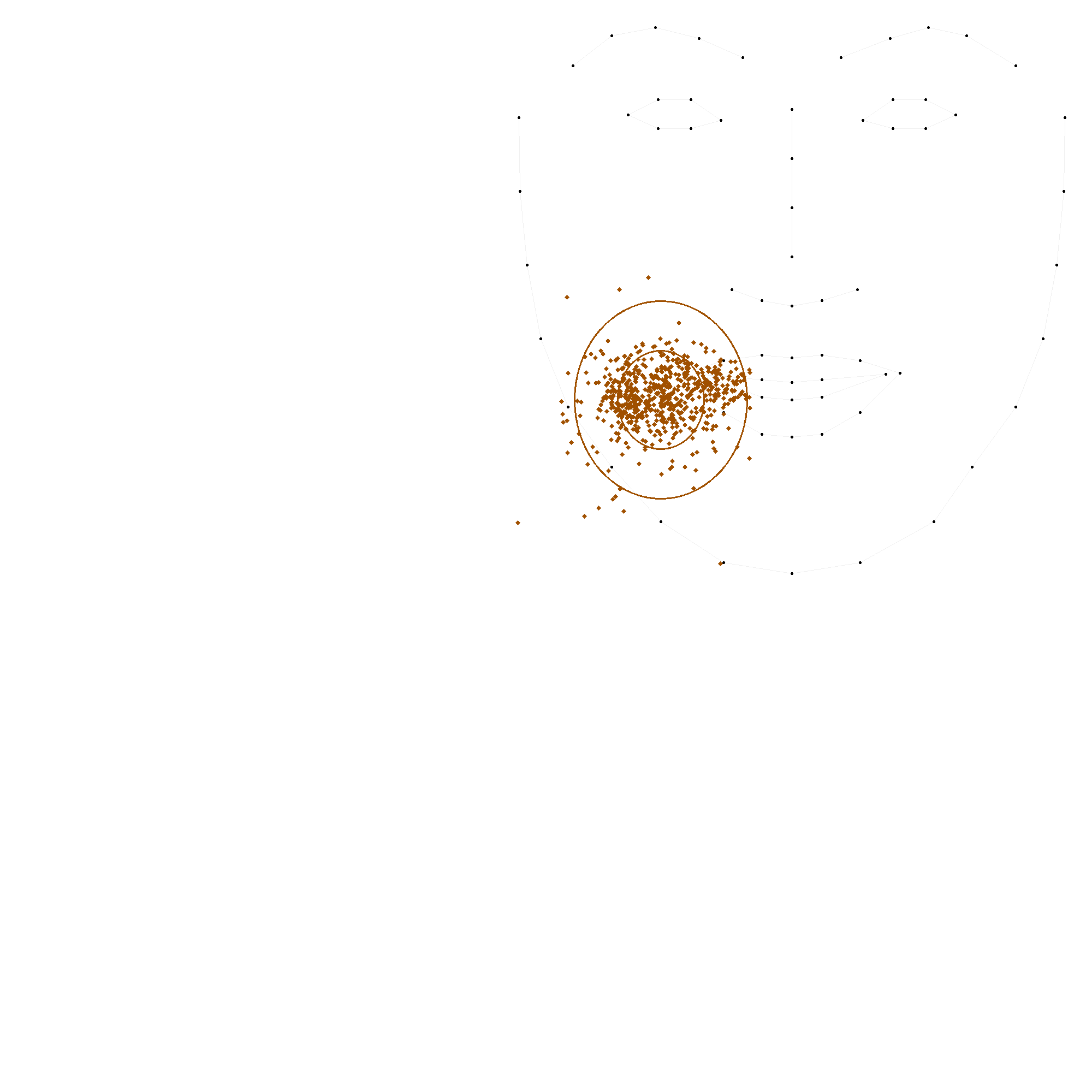
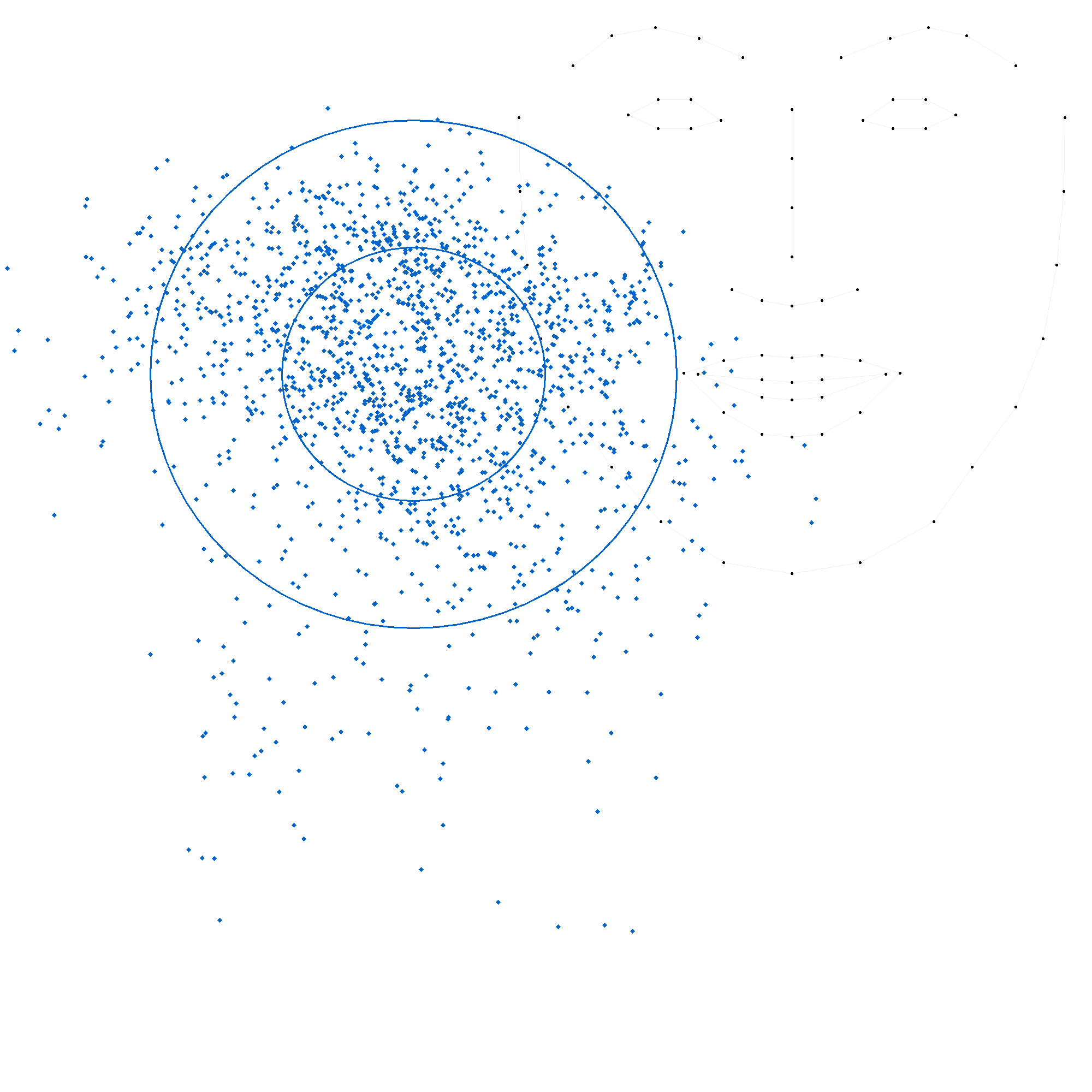
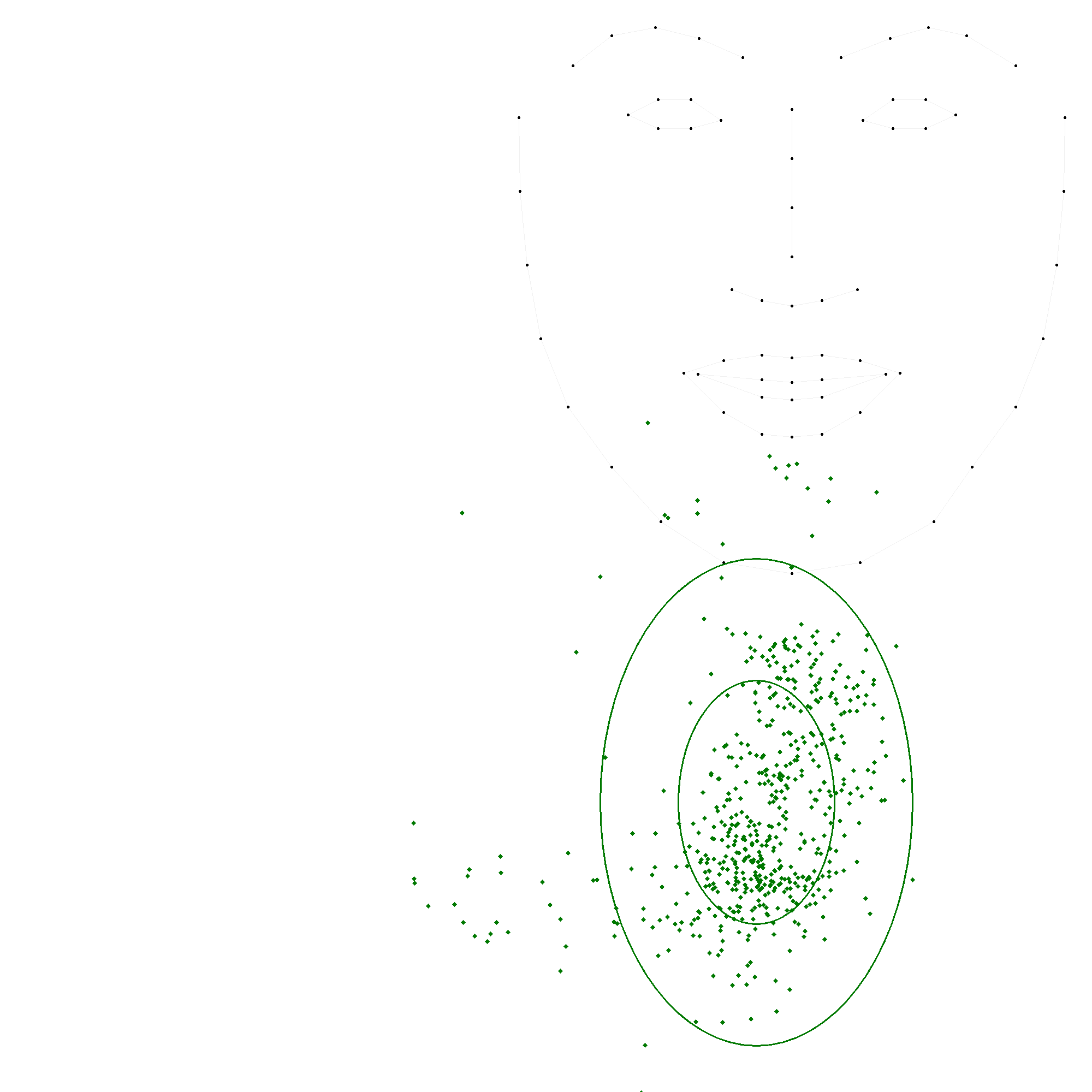
Les figures suivantes illustrent chacune des positions, avec une ellipse représentant l'écart-type et une autre ellipse correspondant à deux fois l'écart-type, cette dernière couvrant généralement environ 95 % des valeurs.

|

|
|
|
|
En comparant ces statistiques avec les modèles précédents, on observe que les positions 'c', 'm' et 't' convergent vers des valeurs similaires. En revanche, les positions 'b' et 's' présentent des variations plus importantes, soulignant la complexité de leur modélisation. La grande variation de la position 's' indique une forte disparité dans les productions.
Statistiques par condition d'enregistrement
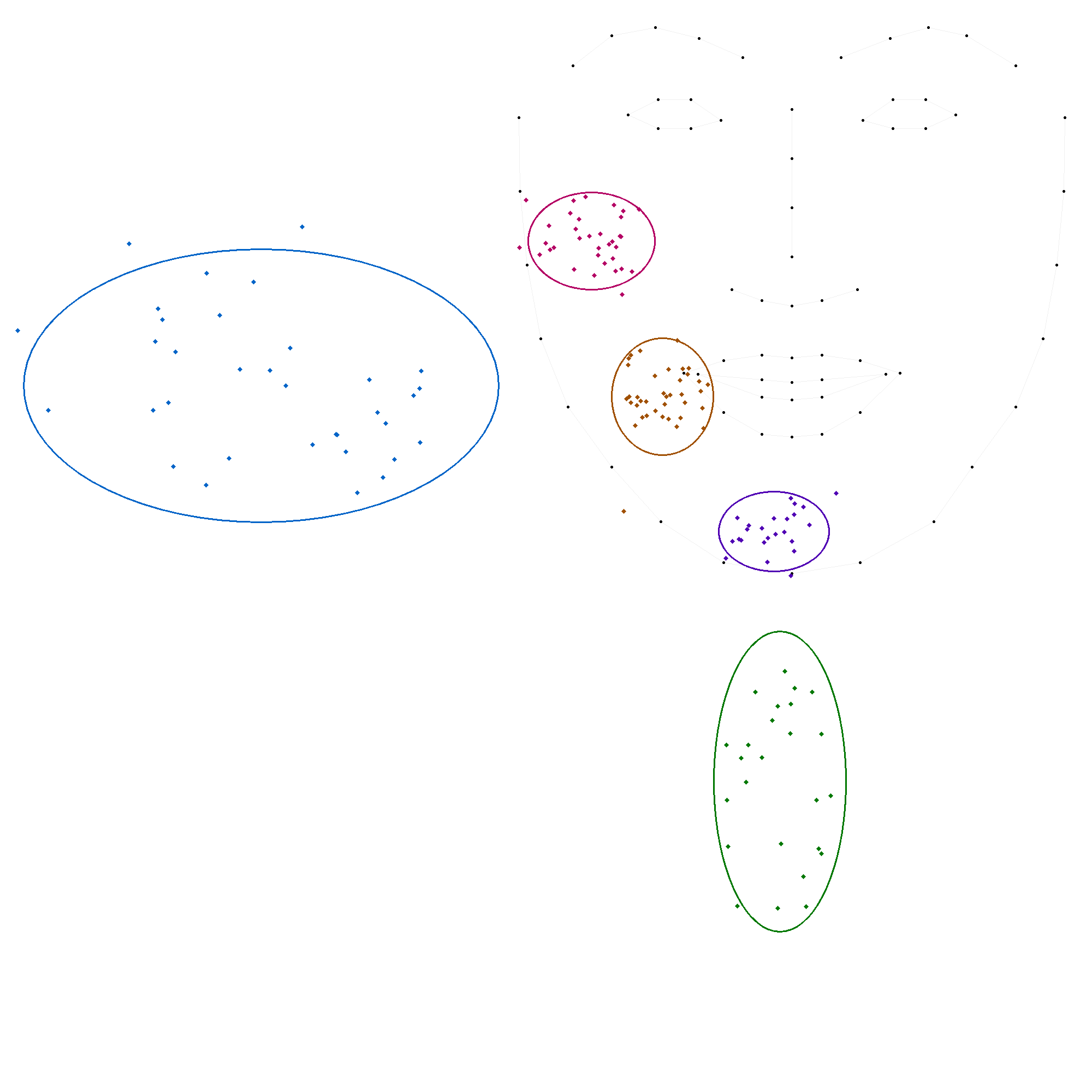
La session "syllabes"
| Position | Nombre | Moyenne | Écart-type |
|---|---|---|---|
| b | 34 | (133, 391) | (58, 45) |
| c | 24 | (467, 923) | (51, 37) |
| m | 38 | (263, 676) | (47, 54) |
| s | 35 | (-472, 656) | (218, 125) |
| t | 25 | (478, 1381) | (61, 138) |
La session "mots et expressions"
| Position | Nombre | Moyenne | Écart-type |
|---|---|---|---|
| b | 45 | (127, 385) | (62, 53) |
| c | 96 | (409, 890) | (81, 87) |
| m | 145 | (253, 676) | (57, 54) |
| s | 279 | (-253, 722) | (253, 248) |
| t | 135 | (441, 1421) | (95, 250) |
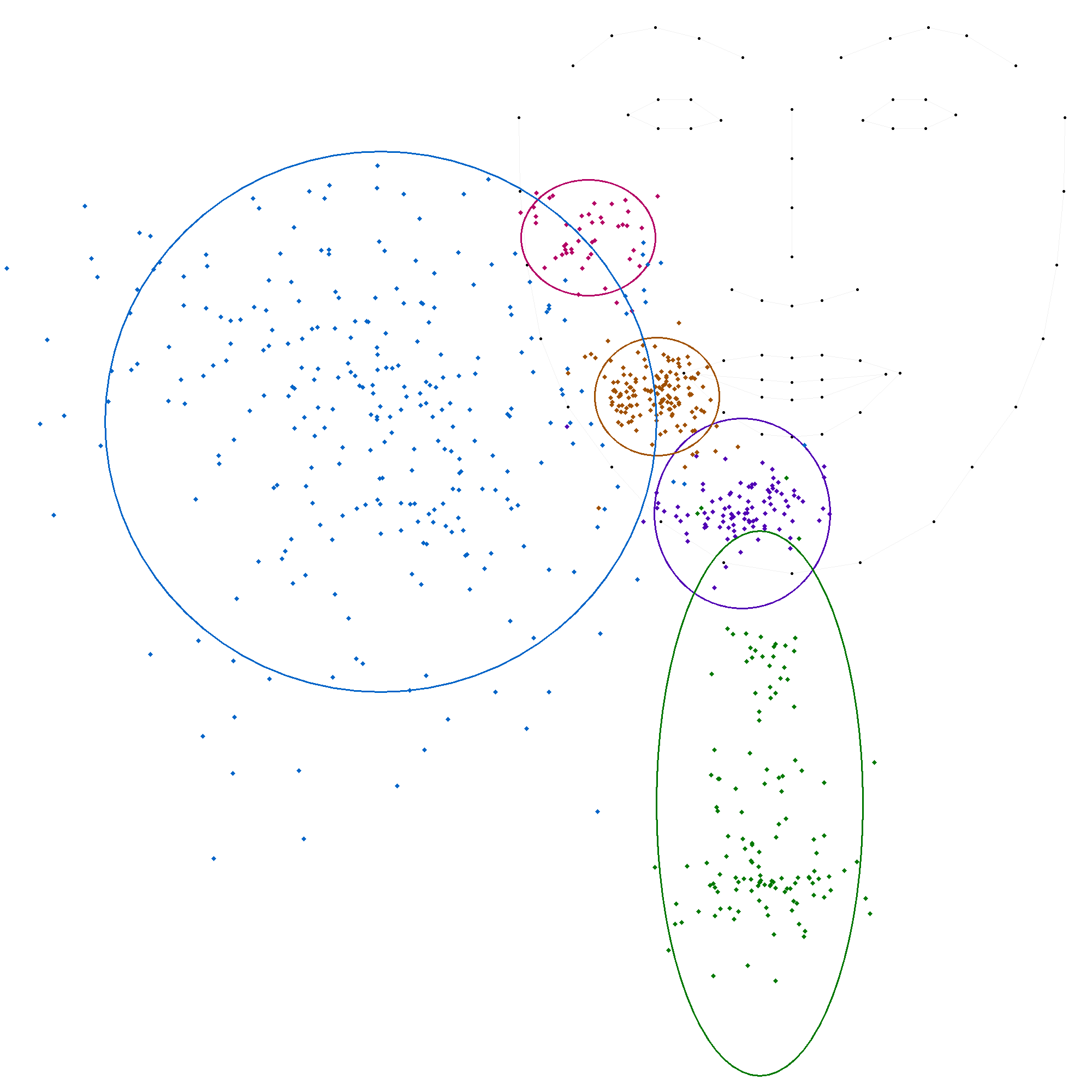
La session "phrases"
| Position | Nombre | Moyenne | Écart-type |
|---|---|---|---|
| b | 76 | (147, 392) | (72, 54) |
| c | 164 | (423, 878) | (95, 53) |
| m | 223 | (272, 684) | (85, 102) |
| s | 704 | (-200, 595) | (214, 213) |
| t | 231 | (455, 1360) | (142, 204) |
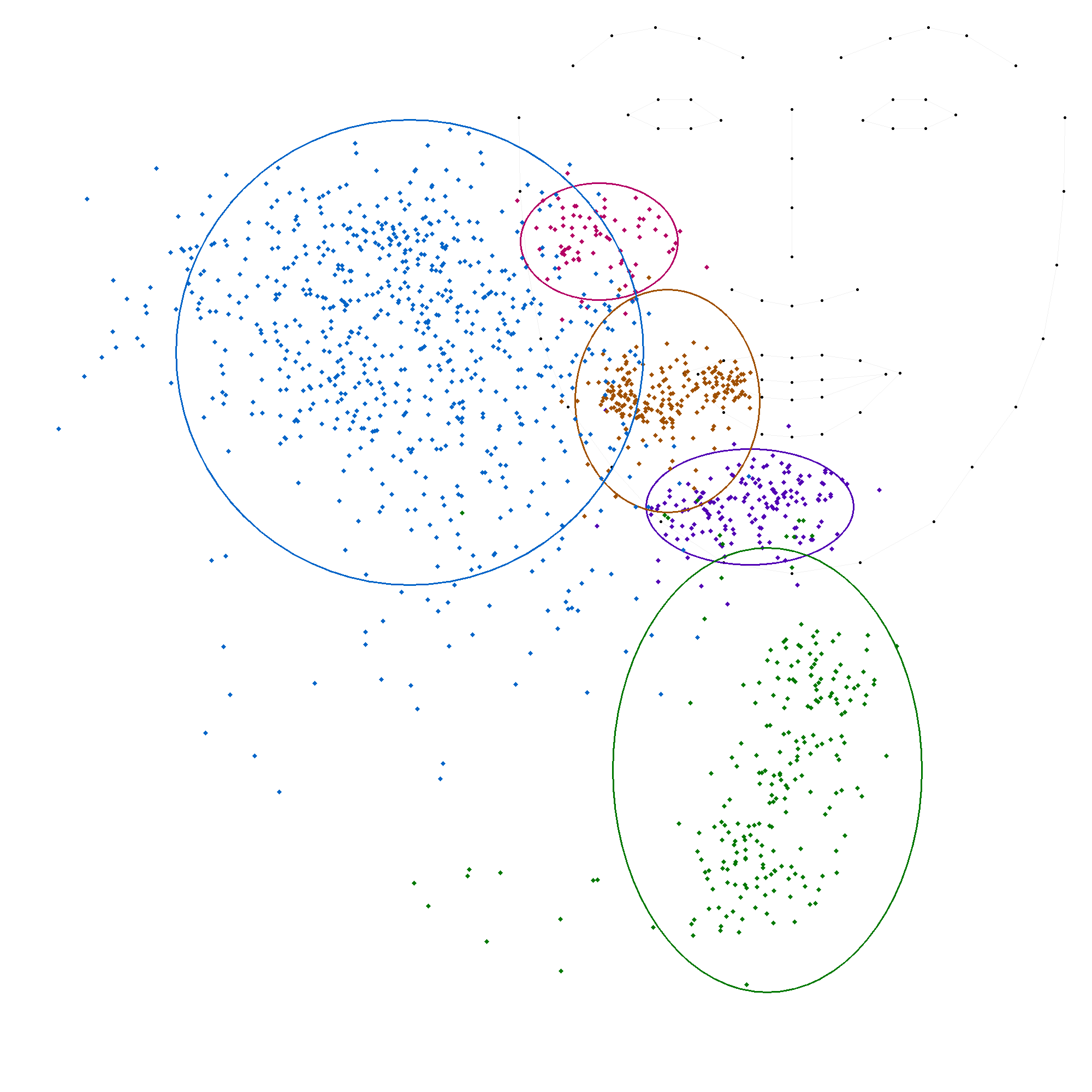
La session "texte"
| Position | Nombre | Moyenne | Écart-type |
|---|---|---|---|
| b | 112 | (151, 422) | (77, 118) |
| c | 239 | (432, 890) | (132, 85) |
| m | 267 | (258, 683) | (83, 100) |
| s | 698 | (-167, 649) | (241, 240) |
| t | 199 | (405, 1478) | (170, 226) |
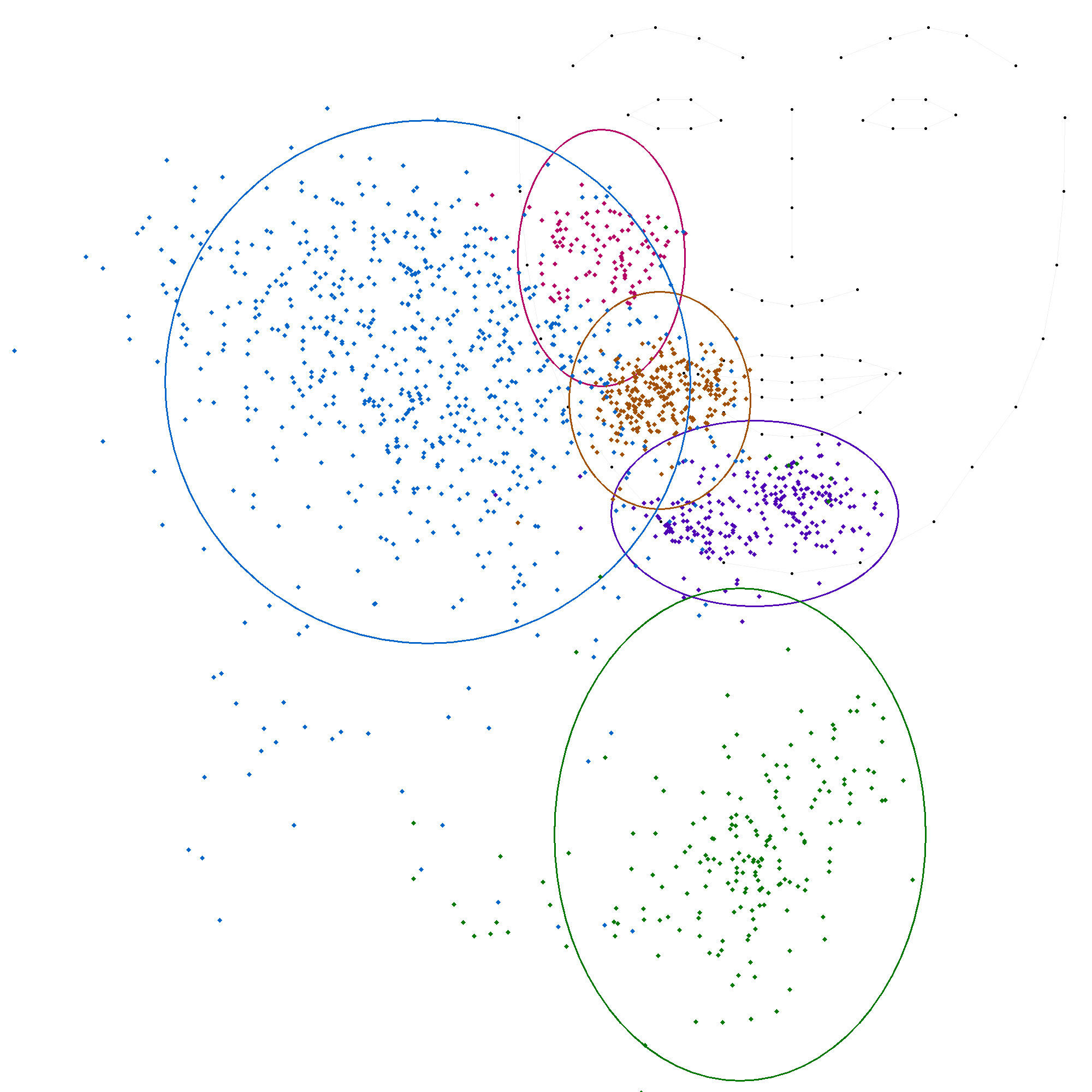
Les conditions "texte" et "phrases" montrent des écart-types plus élevés, tandis que "mots" et "syllabes" sont plus bas. Cela indique une plus grande dispersion des données, suggérant une moins grande précision ou une plus grande variabilité dans le positionnement des voyelles lors de tâches plus complexes. Cela suggère que la condition influence la précision de la position, probablement car le débit plus rapide affecte la précision du mouvement. Le débit et l'intention pédagogique semblent donc influencer la précision de la position des voyelles.
Nous observons en effet que :
- La position 'b' (pommette) montre une variabilité croissante avec la complexité de la tâche, avec les écarts-types les plus élevés dans la condition "texte".
- La position 'c' (menton) présente également une variabilité croissante, en particulier pour l'axe des abscisses.
- La position 'm' (bouche) suit une tendance similaire, avec une variabilité accrue dans les conditions "phrases" et "texte".
- La position 's' (côté du visage) présente une très forte variabilité dans toutes les conditions.
- La position 't' (gorge) présente une forte variabilité sur les ordonnées, et cette variabilité augmente avec la complexité de la tâche.
Les tâches ayant pour consigne une lecture la plus naturelle possible, impliquent un débit de parole plus rapide, ce qui peut entraîner une moins grande précision dans les mouvements de la main. L'intention pédagogique, présente dans les conditions "mots" et "syllabes", pourrait également contribuer à une plus grande précision. Lorsque les codeurs sont invités à montrer le code comme s'ils l'enseignaient, ils peuvent être plus attentifs à la précision de leurs mouvements.
Dans tous les cas, la position sur le côté est très variable, ce qui indique qu'elle est la plus difficile à stabiliser, comme V. Attina (2005) y faisait déjà référence. On observe en outre que la position à la gorge est elle-aussi très variable sur les ordonnées, ce qui indique que la hauteur de la main est difficile à stabiliser.
L'analyse des données par condition révèle des variations intéressantes dans le positionnement des voyelles, suggérant que la nature de la tâche influence la précision et la variabilité des mouvements.
Statistiques par locuteur
La locutrice-codeuse 'CH'
| Position | Nombre | Moyenne | Écart-type |
|---|---|---|---|
| b | 35 | (84, 424) | (48, 195) |
| c | 105 | (308, 916) | (97, 76) |
| m | 106 | (200, 684) | (45, 123) |
| s | 365 | (-230, 775) | (190, 209) |
| t | 90 | (409, 1419) | (152, 363) |
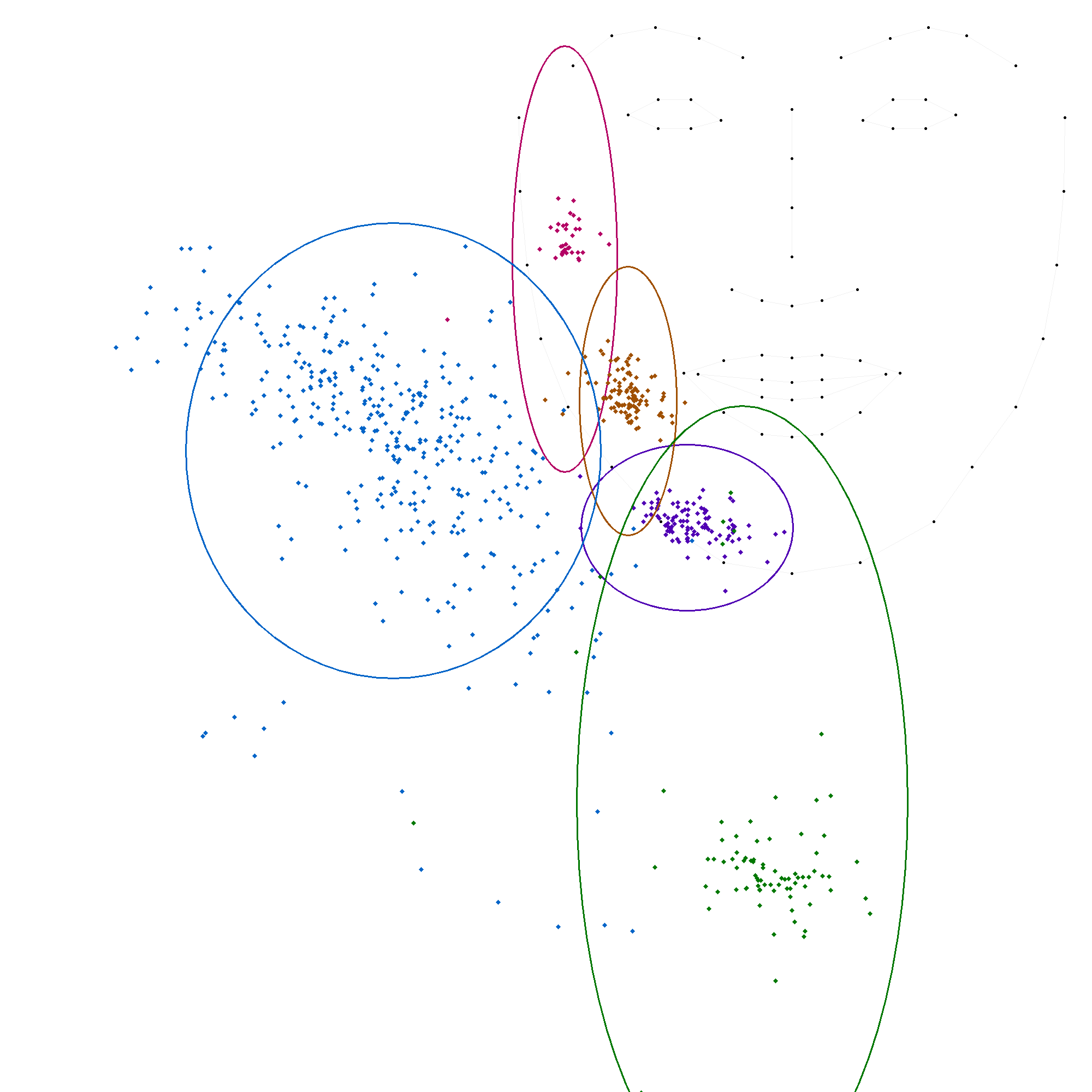
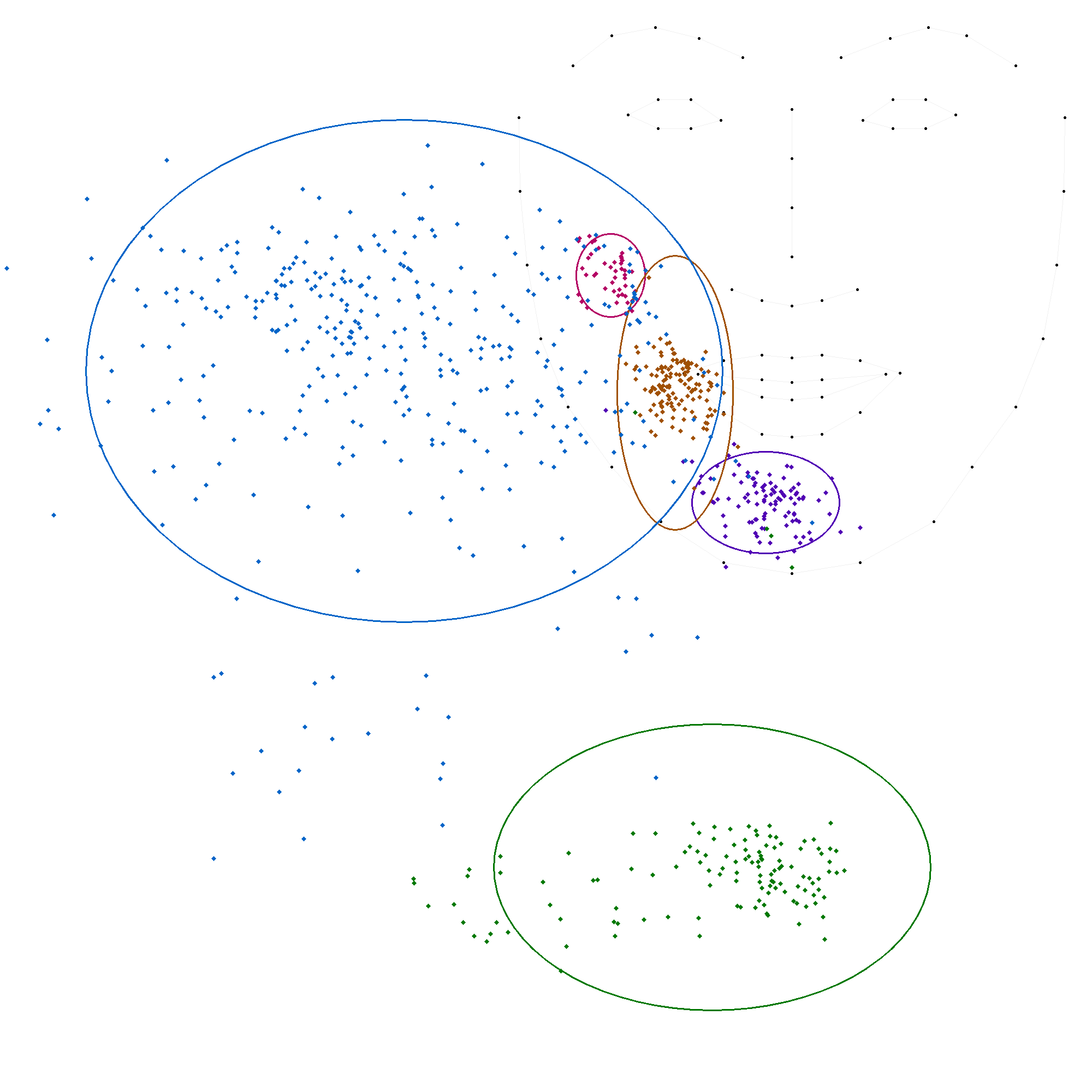
La locutrice-codeuse 'VT'
| Position | Nombre | Moyenne | Écart-type |
|---|---|---|---|
| b | 67 | (180, 365) | (51, 33) |
| c | 137 | (487, 892) | (114, 83) |
| m | 129 | (260, 709) | (61, 70) |
| s | 375 | (26, 601) | (163, 198) |
| t | 105 | (466, 1341) | (64, 160) |
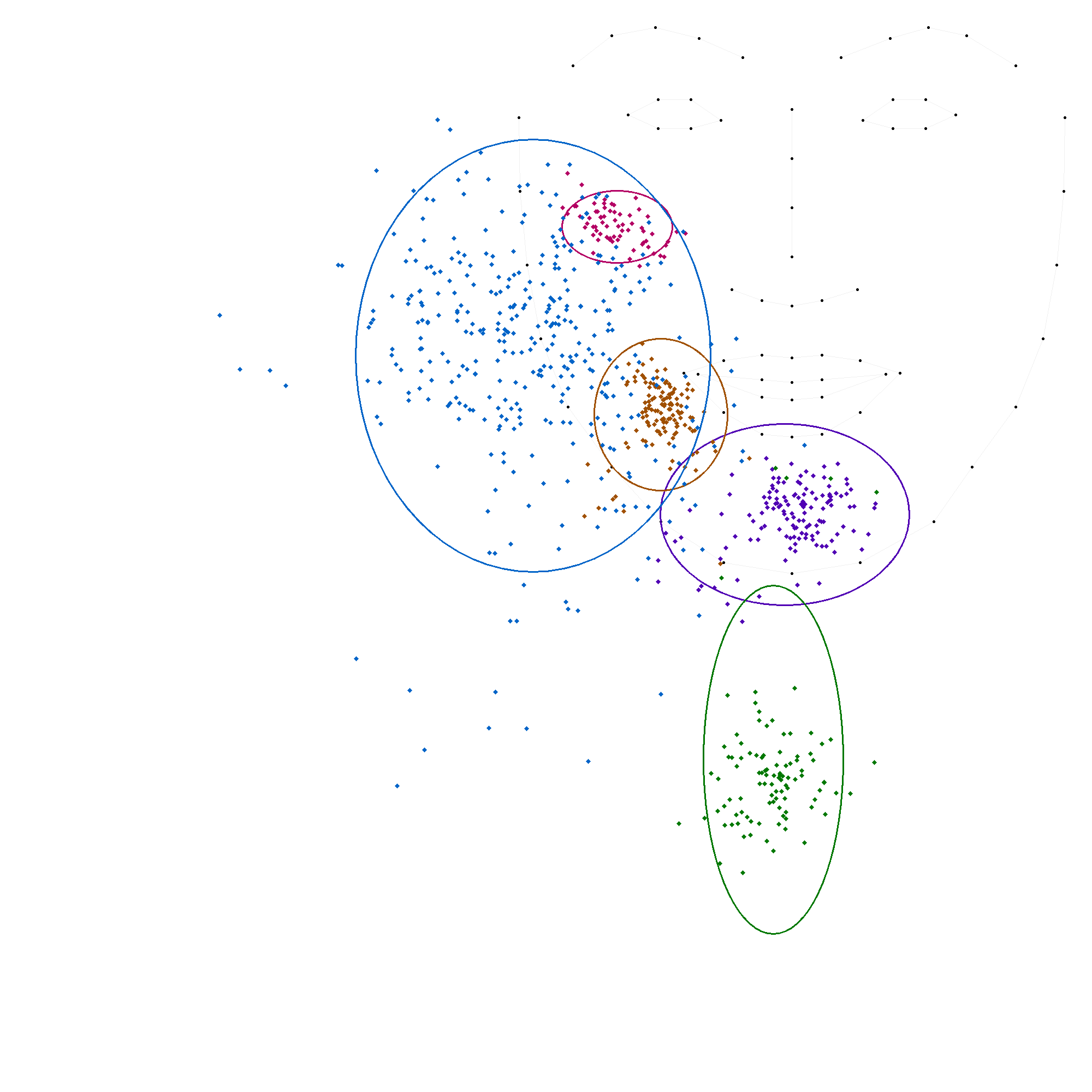
La locutrice-codeuse 'AM'
| Position | Nombre | Moyenne | Écart-type |
|---|---|---|---|
| b | 32 | (34, 379) | (46, 69) |
| c | 91 | (363, 905) | (52, 44) |
| m | 129 | (186, 698) | (42, 70) |
| s | 221 | (-294, 791) | (197, 218) |
| t | 113 | (385, 1582) | (60, 126) |
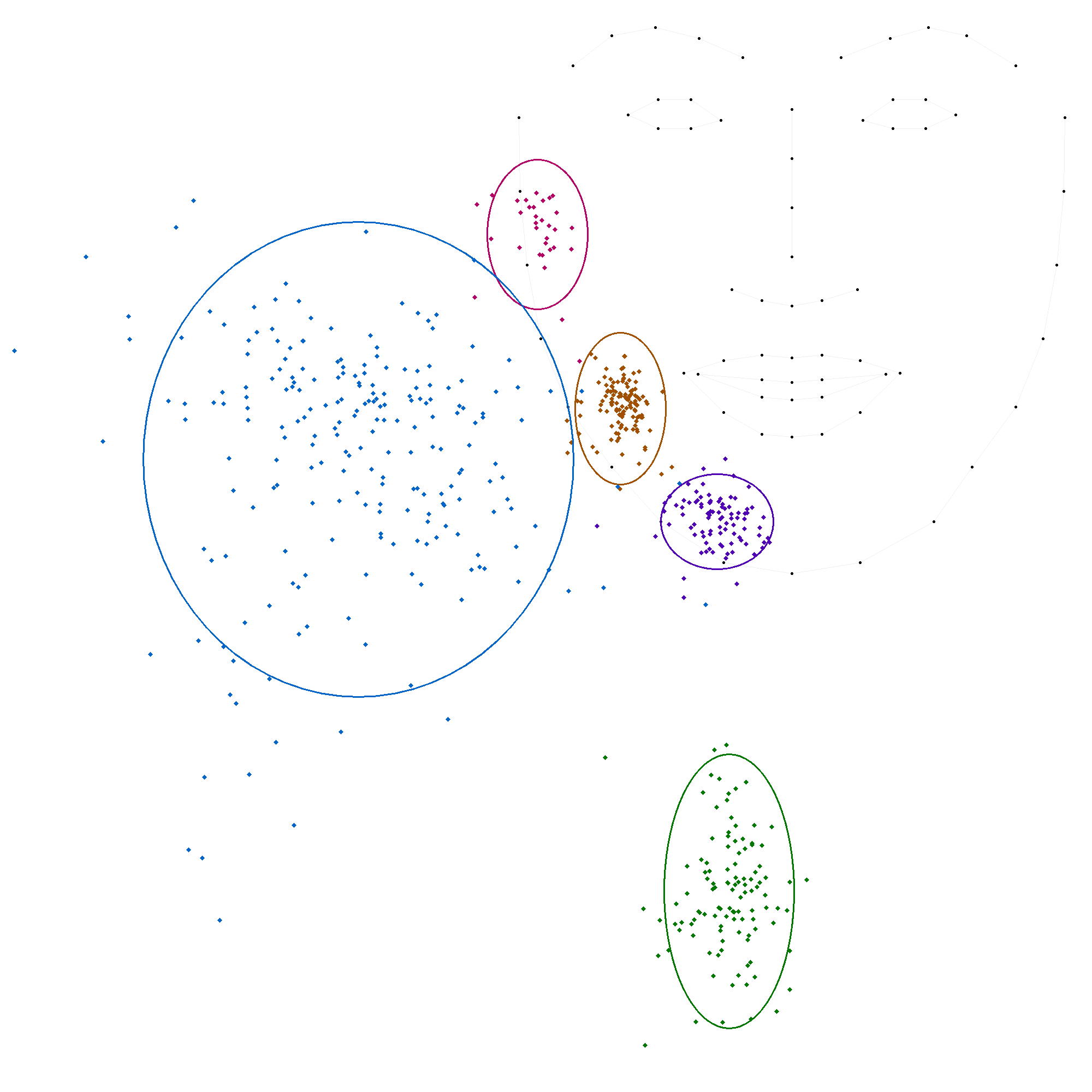
La locutrice-codeuse 'ML'
| Position | Nombre | Moyenne | Écart-type |
|---|---|---|---|
| b | 31 | (225, 371) | (53, 38) |
| c | 92 | (499, 845) | (64, 42) |
| m | 152 | (347, 654) | (47, 34) |
| s | 448 | (-253, 470) | (213, 149) |
| t | 148 | (537, 1242) | (83, 105) |
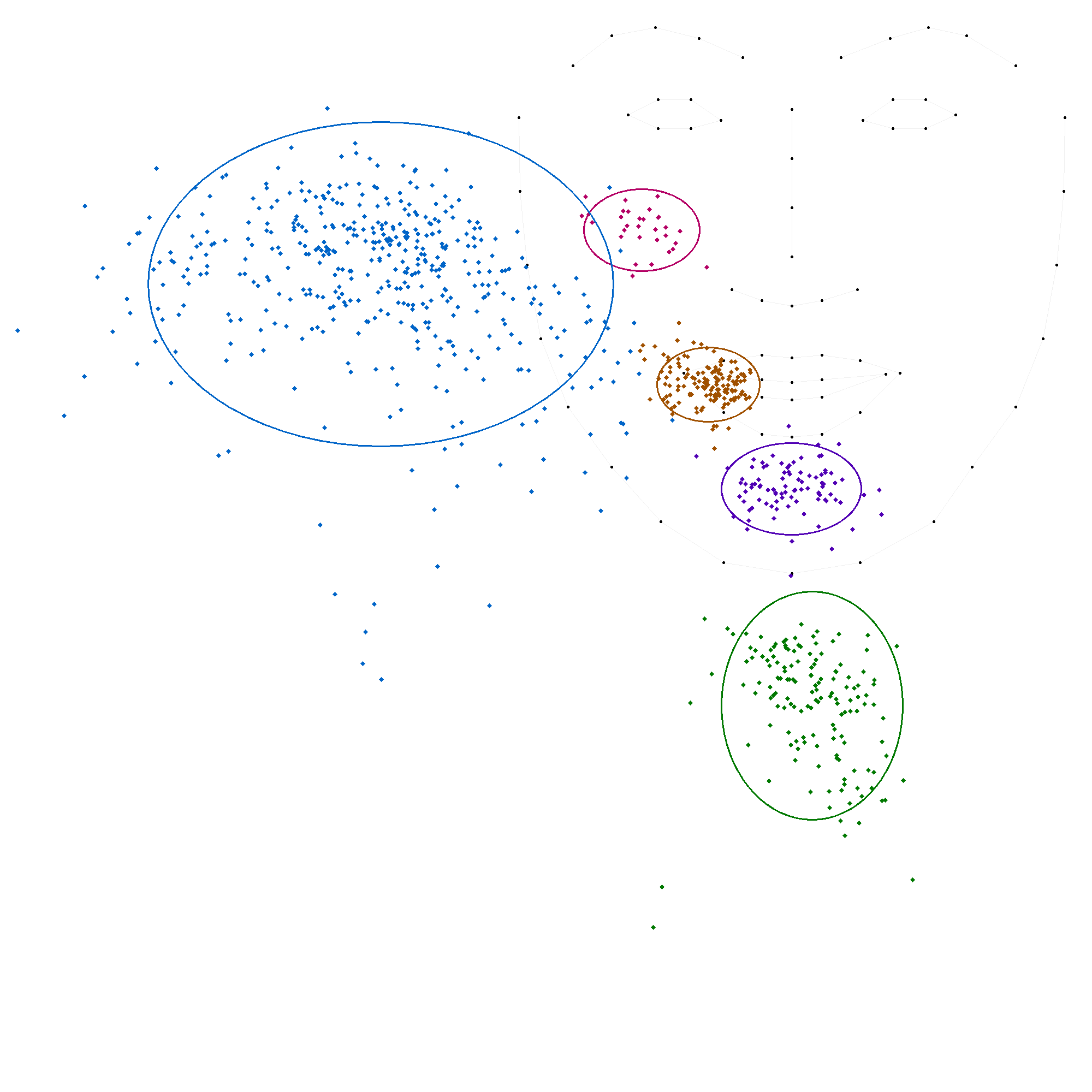
La locutrice-codeuse 'LM'
| Position | Nombre | Moyenne | Écart-type |
|---|---|---|---|
| b | 46 | (168, 454) | (32, 38) |
| c | 104 | (452, 870) | (68, 47) |
| m | 140 | (286, 669) | (53, 126) |
| s | 379 | (-210, 629) | (292, 230) |
| t | 129 | (354, 1538) | (200, 131) |
Interprétation des résultats
L'analyse des données par locuteur révèle une variabilité significative dans le positionnement des voyelles, confirmant l'hypothèse de différences inter-individuelles. Bien que la structure fondamentale du code LfPC reste stable, la manière dont chaque codeur l'applique présente des variations notables.
Les écarts-types, en particulier pour les positions 's' (côté du visage) et 't' (gorge), montrent une dispersion importante des données, indiquant une hétérogénéité dans la manière dont chacun des codeurs codent ces deux positions. Les moyennes varient également d'un codeur à l'autre, bien que dans une moindre mesure, ce qui suggère que chaque codeur a sa propre interprétation du code LfPC.
- La position 'b' (pommette) présente une variabilité modérée, avec des écarts-types allant de 32 à 53 pour l'axe des abscisses et de 33 à 195 pour l'axe des ordonnées. Ce dernier écart-type élevé est celui de la codeuse CH, et il est le seul à fortement s'éloigner des autres.
- La position 'c' (menton) est relativement stable, avec des écarts-types plus faibles, ce qui indique une plus grande cohérence dans la manière dont les codeurs codent cette position.
- La position 'm' (bouche) présente également une variabilité modérée, avec des écarts-types similaires à ceux de la position 'b'.
- La position 's' (côté du visage) est la plus variable, avec des écarts-types élevés pour les deux axes, ce qui confirme l'hétérogénéité observée précédemment.
- La position 't' (gorge) a elle aussi une forte variabilité sur les ordonnées seulement.
L'analyse des données par locuteur met en évidence la stabilité du code LfPC, qui se traduit par une cohérence globale dans le positionnement des voyelles. Cependant, elle révèle également des variations inter-individuelles significatives, en particulier pour les positions 's' et 't'.
Nouveau modèle possible
Sur la base des analyses faites précédemment, il est possible de définir les valeurs à utiliser pour le modèle 4.
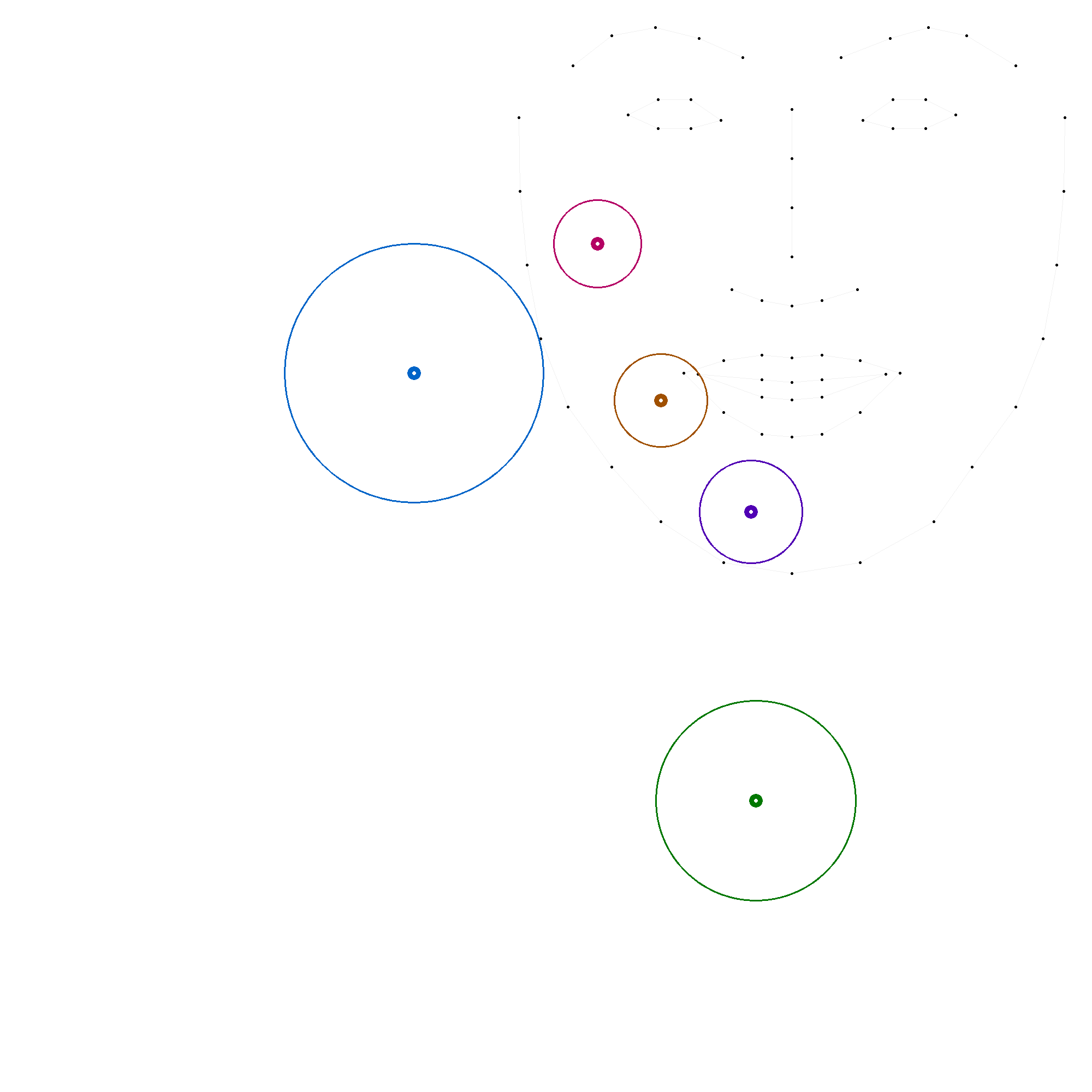
En résumé, le modèle 4, basé sur une analyse statistique exhaustive, confirme certaines tendances observées dans les modèles précédents, tout en révélant des variations significatives, notamment pour la position 's'.
Exemple de vidéo codée avec ce modèle
Accès et utilisation du système
Les modèles proposés sont distribués sous les termes de la licence GNU GPL v3. Ils font partie du logiciel SPPAS. Les modèles 1 et 2 sont disponibles depuis la version 4.22, tandis que les modèles 3 et 4 ont été intégrés dans la version 4.25 : https://sppas.org/.
Pour obtenir le codage de ce système sur la démo proposée dans SPPAS, il est possible d'utiliser l'interface graphique de SPPAS, ou la commande en ligne suivante :
> python sppas/bin/cuedspeech.py -I demo/demo.mp4 -l fra --createvideo=true --handsset=brigitte
Il faut ajouter l'option "facepos" pour choisir le numéro du modèle comme décrit dans ce document. Cette commande permet de créer trois fichiers : deux fichiers de description au format XML qui contiennent l'ensemble des informations prédites par le système, ainsi que la vidéo codée automatiquement.
Contributeurs
Développement logiciel : Brigitte Bigi (LPL)
Analyse des données : Brigitte Bigi (LPL)
Expertise du codage : Datha
À propos
- Rédaction du document : Brigitte Bigi
- Licence du document : GNU documentation libre - FDL 1.3
- Copyright 2025 Brigitte Bigi, CNRS, Laboratoire Parole et Langage, France
- URL de ce document : https://auto-cuedspeech.org/wp4l2.html
- Dernière mise à jour : 31 mars 2025