Livrable WP1 - L2 : Clés LfPC
Contexte et objectifs
Description du corpus
CLeLfPC - Corpus de Lecture en LfPC, contient des enregistrements audio/vidéo de lecture à voix haute en codant en Langue française Parlée Complétée. Le corpus a été enregistré en août 2021 à l'occasion du stage organisé par l'ALPC (https://alpc.asso.fr).
Le corpus est constitué des enregistrements de 25 thèmes par 23 participants. Une série de 10 thèmes de lecture avait été établie, elle peut être consultée à cette adresse : https://sppas.org/LFPC/.
Chacun des 10 thèmes est constitué de 4 sessions distinctes :
- enregistrement audio/vidéo de 32 syllabes "CV" isolées (1 seule clé produite pour chaque syllabe),
- enregistrement audio/vidéo de 32 mots ou expressions,
- enregistrement audio/vidéo de phrases isolées,
- enregistrement audio/vidéo d'un texte.
Objectif
Le corpus doit être enrichi d'annotations pour pouvoir être exploité dans le cadre de ce projet. Ce livrable concerne l'annotation en clés du corpus, c'est-à-dire que nous avons observé quelles sont les clés qui ont été produites par les locuteurs du corpus durant la lecture des thèmes.
Dix thèmes ont été annotés automatiquement en clés, dont 5 ont été vérifiés manuellement.
En savoir plus...
- Publication de référence : Brigitte Bigi (2023). An analysis of produced versus predicted French Cued Speech keys. 10th Language & Technology Conference: Human Language Technologies as a Challenge for Computer Science and Linguistics, ISBN: 978-83-232-4176-8, pp. 24-28, Poznań, Pologne.
- Fiche technique du corpus
- Accès aux données
Enregistrements annotés
Ci-dessous, la liste des enregistrements pour lesquels nous disposons de la segmentation phonétique ainsi que des clés prédites, et leur description :
- 01_CH_dd640f, annotation corrigée manuellement : Thème 1, femme, droitière, codage main droite, codeuse professionnelle
- 02_VT_dd640f, annotation corrigée manuellement : Thème 2, femme, droitière, codage main droite, codeuse professionnelle
- 03_AM_dd630f, annotation corrigée manuellement : Thème 3, femme, droitière, codage main droite, codeuse professionnelle
- 04_RJ_gg330m, annotation automatique : Thème 4, homme, gaucher, codage main gauche
- 05_ML_gg540f, annotation corrigée manuellement : Thème 5, femme, gauchère, codage main gauche
- 06_FL_dd620f, annotation automatique : Thème 6, femme, droitière, codage main droite, codeuse professionnelle
- 07_LW_dd641f, annotation automatique : Thème 7, femme, droitière, codage main droite, avec surdité
- 08_HH_gd440f, annotation automatique : Thème 8, femme, droitière, codage main gauche
- 09_LM_gd640f, annotation corrigée manuellement : Thème 9, femme, droitière, codage main gauche, codeuse professionnelle
- 10_ED_dd320f, annotation automatique : Thème 10, femme, droitière, codage main droite
Les fichiers (audios, vidéos, annotations) sont déposés sous les termes de la licence publique CC-By-NC-4.0. Ils peuvent être téléchargés à partir de la version 7 du dépôt https://www.ortolang.fr par tout membre d'un Etablissement Supérieur de la Recherche. Pour toute autre demande, envoyer un e-mail à brigitte.bigi[at]cnrs.fr.
Description des étapes réalisées pour obtenir les annotations
Annotations automatiques avec SPPAS
Le système de génération automatique des clés LfPC implémenté dans SPPAS a été utilisé pour générer automatiquement les annotations, avec la version 1.5 du fichier de règles, c'est-à-dire la version validée par les experts du projet, et dont le résultat a été vérifié par les acteurs de terrain.
Ce système a utilisé les phonèmes alignés (c.f. WP1-L1) et a généré les clés qui sont supposément produites, comme illustré dans la figure ci-après.
La figure illustre les lignes temporelles suivantes :
- transcription orthographique
- alignement temporel des phonèmes
- alignement temporel des mots
- la séquence des phonèmes des clés générées automatiquement
- la structure des phonèmes des clés générées automatiquement (C=Consonne, V=voyelle)
- le code des clés générées automatiquement (c.f. WP2-L1)
- la structure des clés générées automatiquement (N=neutre)
- idem (4)
- le code des clés après correction manuelle
- la structure des clés après correction manuelle
Corrections manuelles avec l'éditeur de SPPAS
Comme illustré par les lignes (9) et (10) de la figure ci-dessus, les codes des clés ont été corrigés manuellement. Pour ce faire, il a fallu visionner les vidéos image-par-image en comparant le code de l'annotation obtenue automatiquement à celui qui est effectivement réalisé par le locuteur de chaque vidéo. Ce travail étant très fastidieux et chronophage, il n'a pu être réalisé que sur une partie des données.
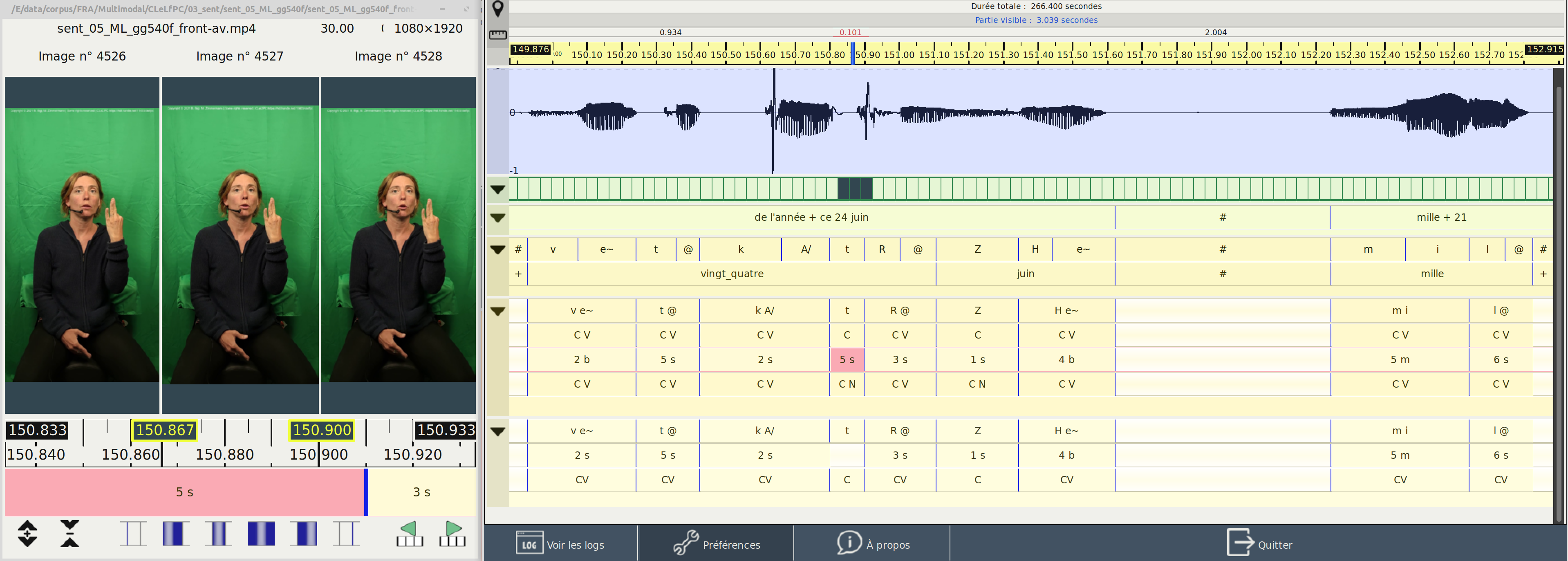
Cette annotation n'a été possible que grâce à l'utilisation de l'éditeur de SPPAS, dont un module a été spécifiquement développé à cette occasion (diffusé depuis la version 4.12). La figure montre cette version, avec notamment une fenêtre qui contient 3 images consécutives de la vidéo ainsi que la ligne d'annotation qui est en cours d'analyse.
L'analyse des clés prédites par le système, versus les clés réellement produites sur les 5 thèmes corrigés manuellement, a fait l'objet de la publication mentionnée dans la section précédente. Cette analyse permet de valider le système proposé, et d'apporter quelques éléments d'information intéressants sur les "habitudes" de codage des codeurs. Une synthèse de cette analyse (en français) peut être consultée dans ce diaporama.
Contributeurs
Annotation manuelle du corpus : Léa Delaporte (août 2023)
Annotation automatique du corpus, gestion des données : Brigitte Bigi (2023)
Développement logiciel : Audric Vachet, Brigitte Bigi (avril-août 2023)
À propos
- Rédaction du document : Brigitte Bigi
- Licence du document : GNU documentation libre - FDL 1.3
- Copyright 2023 Brigitte Bigi, CNRS, Laboratoire Parole et Langage, France
- URL du document : https://auto-cuedspeech.org/wp1l2.html
- Dernière mise à jour : novembre 2023